WebGPU 컴퓨트 셰이더 - 이미지 히스토그램
이 문서는 컴퓨트 셰이더 기초 문서에서 이어집니다.
이 글은 긴 2부작 문서이며, 최적화를 위해 여러 단계를 거칠 것입니다. 이 최적화는 속도를 빠르게 만들지만 안타깝게도 출력 결과는 변하지 않으므로 각 단계는 이전 단계와 동일하게 보일 것입니다.
또한, 속도와 타이밍에 대해 언급하겠지만, 타이밍 코드를 추가하면 문서와 예제가 더 길어지므로 타이밍은 다른 문서에서 다루고, 이 문서에서는 제 측정 결과만 언급하고 실행 가능한 예제를 제공하겠습니다. 이 문서가 앞으로 여러분이 컴퓨트 셰이더를 만들 때 참조할 수 있는 하나의 예제가 되기를 바랍니다.
이미지 히스토그램은 이미지의 모든 픽셀을 그 값 또는 값의 측정 기준에 따라 합산하는 것입니다.
예를 들어, 이 6x7 이미지를 보겠습니다.
이 이미지는 다음과 같은 색상들을 가지고 있습니다.
각 색상에 대해 휘도(밝기) 레벨을 계산할 수 있습니다. 온라인에서 찾은 공식은 다음과 같습니다.
// 휘도 값을 0에서 1 사이로 반환합니다.
// r, g, b는 각각 0에서 1 사이의 값입니다.
function srgbLuminance(r, g, b) {
// from: https://www.w3.org/WAI/GL/wiki/Relative_luminance
return r * 0.2126 +
g * 0.7152 +
b * 0.0722;
}
이를 사용하여 각 값을 휘도 레벨로 변환할 수 있습니다.
"빈(bin)"의 개수를 정할 수 있습니다. 3개의 빈으로 정해봅시다. 그런 다음 이러한 휘도 값을 양자화하여 "빈"을 선택하고 각 빈에 맞는 픽셀 수를 합산할 수 있습니다.
마지막으로 이러한 빈의 값을 그래프로 그릴 수 있습니다.
그래프는 어두운 픽셀(🟦 18)이 중간 밝기 픽셀(🟥 16)보다 많고, 밝은 픽셀(🟨 8)은 훨씬 적다는 것을 보여줍니다. 단 3개의 빈으로는 그다지 흥미롭지 않습니다. 하지만 이런 사진을 찍으면

픽셀 휘도 값을 세고, 256개의 빈으로 분리하여 그래프로 그리면 다음과 같은 결과를 얻습니다.
이미지 히스토그램을 계산하는 것은 매우 간단합니다. 먼저 JavaScript로 해봅시다.
ImageData 객체가 주어지면 히스토그램을 생성하는 함수를 만들어 봅시다.
function computeHistogram(numBins, imgData) {
const {width, height, data} = imgData;
const bins = new Array(numBins).fill(0);
for (let y = 0; y < height; ++y) {
for (let x = 0; x < width; ++x) {
const offset = (y * width + x) * 4;
const r = data[offset + 0] / 255;
const g = data[offset + 1] / 255;
const b = data[offset + 2] / 255;
const v = srgbLuminance(r, g, b);
const bin = Math.min(numBins - 1, v * numBins) | 0;
++bins[bin];
}
}
return bins;
}
위에서 볼 수 있듯이, 각 픽셀을 순회합니다. 이미지에서 r, g, b를 추출합니다. 휘도 값을 계산합니다. 이를 빈 인덱스로 변환하고 해당 빈의 카운트를 증가시킵니다.
이 데이터가 있으면 그래프로 그릴 수 있습니다. 주요 그래프 함수는 각 빈에 대해 스케일과 캔버스 높이를 곱한 선을 그립니다.
ctx.fillStyle = '#fff';
for (let x = 0; x < numBins; ++x) {
const v = histogram[x] * scale * height;
ctx.fillRect(x, height - v, 1, v);
}
스케일을 결정하는 것은 개인적인 선택인 것 같습니다. 좋은 공식을 알고 계시다면 댓글을 남겨주세요. 😅 인터넷을 둘러본 결과 다음과 같은 스케일 공식을 만들었습니다.
const numBins = histogram.length; const max = Math.max(...histogram); const scale = Math.max(1 / max, 0.2 * numBins / numEntries);
여기서 numEntries는 이미지의 총 픽셀 수(즉, width * height)이며,
기본적으로 가장 많은 값을 가진 빈이 그래프의 상단에 닿도록 스케일을 조정하지만,
해당 빈이 너무 크면 보기 좋은 그래프를 생성하는 비율을 사용합니다.
모두 합치면 2D 캔버스를 만들고 그립니다.
function drawHistogram(histogram, numEntries, height = 100) {
const numBins = histogram.length;
const max = Math.max(...histogram);
const scale = Math.max(1 / max, 0.2 * numBins / numEntries);
const canvas = document.createElement('canvas');
canvas.width = numBins;
canvas.height = height;
document.body.appendChild(canvas);
const ctx = canvas.getContext('2d');
ctx.fillStyle = '#fff';
for (let x = 0; x < numBins; ++x) {
const v = histogram[x] * scale * height;
ctx.fillRect(x, height - v, 1, v);
}
}
이제 이미지를 로드해야 합니다. 이미지 로딩 문서에서 작성한 코드를 사용하겠습니다.
async function main() {
const imgBitmap = await loadImageBitmap('resources/images/pexels-francesco-ungaro-96938-mid.jpg');
이미지에서 데이터를 가져와야 합니다. 이를 위해 이미지를
2D 캔버스에 그린 다음 getImageData를 사용할 수 있습니다.
function getImageData(img) {
const canvas = document.createElement('canvas');
// 캔버스를 이미지와 같은 크기로 만듭니다
canvas.width = img.naturalWidth;
canvas.height = img.naturalHeight;
const ctx = canvas.getContext('2d');
ctx.drawImage(img, 0, 0);
return ctx.getImageData(0, 0, canvas.width, canvas.height);
}
ImageBitmap을 표시하는 함수도 작성하겠습니다.
function showImageBitmap(imageBitmap) {
const canvas = document.createElement('canvas');
canvas.width = imageBitmap.width;
canvas.height = imageBitmap.height;
const bm = canvas.getContext('bitmaprenderer');
bm.transferFromImageBitmap(imageBitmap);
document.body.appendChild(canvas);
}
이미지가 너무 크게 표시되지 않도록 CSS를 추가하고 배경색도 지정합니다.
canvas {
display: block;
max-width: 256px;
border: 1px solid #888;
background-color: #333;
}
그런 다음 위에서 작성한 함수들을 호출하기만 하면 됩니다.
async function main() {
const imgBitmap = await loadImageBitmap('resources/images/pexels-francesco-ungaro-96938-mid.jpg');
const imgData = getImageData(imgBitmap);
const numBins = 256;
const histogram = computeHistogram(numBins, imgData);
showImageBitmap(imgBitmap);
const numEntries = imgData.width * imgData.height;
drawHistogram(histogram, numEntries);
}
그리고 여기 이미지 히스토그램이 있습니다.
JavaScript 코드가 무엇을 하는지 따라가기 쉬웠기를 바랍니다. 이제 WebGPU로 변환해봅시다!
GPU에서 히스토그램 계산하기
가장 명확한 솔루션부터 시작하겠습니다. JavaScript computeHistogram 함수를
WGSL로 직접 변환하겠습니다.
휘도 함수는 매우 간단합니다. 다시 JavaScript입니다.
// 휘도 값을 0에서 1 사이로 반환합니다.
// r, g, b는 각각 0에서 1 사이의 값입니다.
function srgbLuminance(r, g, b) {
// from: https://www.w3.org/WAI/GL/wiki/Relative_luminance
return r * 0.2126 +
g * 0.7152 +
b * 0.0722;
}
그리고 여기 해당하는 WGSL입니다.
// from: https://www.w3.org/WAI/GL/wiki/Relative_luminance
const kSRGBLuminanceFactors = vec3f(0.2126, 0.7152, 0.0722);
fn srgbLuminance(color: vec3f) -> f32 {
return saturate(dot(color, kSRGBLuminanceFactors));
}
"내적(dot product)"의 약자인 dot 함수는 한 벡터의 모든 요소를
다른 벡터의 해당 요소와 곱한 다음 결과를 더합니다. 위의 vec3f의 경우 다음과 같이 정의할 수 있습니다.
fn dot(a: vec3f, b: vec3f) -> f32 {
return a.x * b.x + a.y * b.y + a.z * b.z;
}
이것이 JavaScript에 있던 것입니다. 주요 차이점은 WGSL에서는
개별 채널 대신 색상을 vec3f로 전달한다는 것입니다.
히스토그램 계산의 주요 부분에 대해, 다시 JavaScript입니다.
function computeHistogram(numBins, imgData) {
const {width, height, data} = imgData;
const bins = new Array(numBins).fill(0);
for (let y = 0; y < height; ++y) {
for (let x = 0; x < width; ++x) {
const offset = (y * width + x) * 4;
const r = data[offset + 0] / 255;
const g = data[offset + 1] / 255;
const b = data[offset + 2] / 255;
const v = srgbLuminance(r, g, b);
const bin = Math.min(numBins - 1, v * numBins) | 0;
++bins[bin];
}
}
return bins;
}
여기 해당하는 WGSL입니다.
@group(0) @binding(0) var<storage, read_write> bins: array<u32>;
@group(0) @binding(1) var ourTexture: texture_2d<f32>;
// from: https://www.w3.org/WAI/GL/wiki/Relative_luminance
const kSRGBLuminanceFactors = vec3f(0.2126, 0.7152, 0.0722);
fn srgbLuminance(color: vec3f) -> f32 {
return saturate(dot(color, kSRGBLuminanceFactors));
}
@compute @workgroup_size(1) fn cs() {
let size = textureDimensions(ourTexture, 0);
let numBins = f32(arrayLength(&bins));
let lastBinIndex = u32(numBins - 1);
for (var y = 0u; y < size.y; y++) {
for (var x = 0u; x < size.x; x++) {
let position = vec2u(x, y);
let color = textureLoad(ourTexture, position, 0);
let v = srgbLuminance(color.rgb);
let bin = min(u32(v * numBins), lastBinIndex);
bins[bin] += 1;
}
}
}
위에서 많이 변경되지 않았습니다. JavaScript에서는 imgData에서 데이터, 너비, 높이를 가져옵니다.
WGSL에서는 textureDimensions 함수에 텍스처를 전달하여 너비와 높이를 가져옵니다.
let size = textureDimensions(ourTexture, 0);
textureDimensions는 텍스처와 밉 레벨(위의 0)을 받아
해당 텍스처의 밉 레벨 크기를 반환합니다.
JavaScript에서 했던 것처럼 텍스처의 모든 픽셀을 순회합니다.
for (var y = 0u; y < size.y; y++) {
for (var x = 0u; x < size.x; x++) {
textureLoad를 호출하여 텍스처에서 색상을 가져옵니다.
let position = vec2u(x, y);
let color = textureLoad(ourTexture, position, 0);
textureLoad는 텍스처의 단일 밉 레벨에서 단일 텍셀을 반환합니다.
텍스처, vec2u 텍셀 위치, 밉 레벨(0)을 받습니다.
휘도 값을 계산하고, 빈 인덱스로 변환하고, 해당 빈을 증가시킵니다.
let position = vec2u(x, y);
let color = textureLoad(ourTexture, position, 0);
+ let v = srgbLuminance(color.rgb);
+ let bin = min(u32(v * numBins), lastBinIndex);
+ bins[bin] += 1;
이제 컴퓨트 셰이더가 있으니 사용해봅시다.
표준 초기화 코드가 있습니다.
async function main() {
const adapter = await navigator.gpu?.requestAdapter();
const device = await adapter?.requestDevice();
if (!device) {
fail('need a browser that supports WebGPU');
return;
}
그런 다음 셰이더를 만듭니다.
const module = device.createShaderModule({
label: 'histogram shader',
code: /* wgsl */ `
@group(0) @binding(0) var<storage, read_write> bins: array<u32>;
@group(0) @binding(1) var ourTexture: texture_2d<f32>;
// from: https://www.w3.org/WAI/GL/wiki/Relative_luminance
const kSRGBLuminanceFactors = vec3f(0.2126, 0.7152, 0.0722);
fn srgbLuminance(color: vec3f) -> f32 {
return saturate(dot(color, kSRGBLuminanceFactors));
}
@compute @workgroup_size(1) fn cs() {
let size = textureDimensions(ourTexture, 0);
let numBins = f32(arrayLength(&bins));
let lastBinIndex = u32(numBins - 1);
for (var y = 0u; y < size.y; y++) {
for (var x = 0u; x < size.x; x++) {
let position = vec2u(x, y);
let color = textureLoad(ourTexture, position, 0);
let v = srgbLuminance(color.rgb);
let bin = min(u32(v * numBins), lastBinIndex);
bins[bin] += 1;
}
}
}
`,
});
셰이더를 실행할 컴퓨트 파이프라인을 만듭니다.
const pipeline = device.createComputePipeline({
label: 'histogram',
layout: 'auto',
compute: {
module,
},
});
이미지를 로드한 후 텍스처를 만들고 데이터를 복사해야 합니다.
텍스처에 이미지 로딩 문서에서
작성한 createTextureFromSource 함수를 사용하겠습니다.
const imgBitmap = await loadImageBitmap('resources/images/pexels-francesco-ungaro-96938-mid.jpg');
const texture = createTextureFromSource(device, imgBitmap);
셰이더가 색상 값을 합산할 스토리지 버퍼를 만들어야 합니다.
const numBins = 256;
const histogramBuffer = device.createBuffer({
size: numBins * 4, // 256 entries * 4 bytes per (u32)
usage: GPUBufferUsage.STORAGE | GPUBufferUsage.COPY_SRC,
});
그리고 결과를 가져와서 그릴 수 있도록 버퍼가 필요합니다.
const resultBuffer = device.createBuffer({
size: histogramBuffer.size,
usage: GPUBufferUsage.COPY_DST | GPUBufferUsage.MAP_READ,
});
텍스처와 히스토그램 버퍼를 파이프라인에 전달하기 위한 바인드 그룹이 필요합니다.
const bindGroup = device.createBindGroup({
label: 'histogram bindGroup',
layout: pipeline.getBindGroupLayout(0),
entries: [
{ binding: 0, resource: histogramBuffer },
{ binding: 1, resource: texture },
],
});
이제 컴퓨트 셰이더를 실행하는 명령을 설정할 수 있습니다.
const encoder = device.createCommandEncoder({ label: 'histogram encoder' });
const pass = encoder.beginComputePass();
pass.setPipeline(pipeline);
pass.setBindGroup(0, bindGroup);
pass.dispatchWorkgroups(1);
pass.end();
히스토그램 버퍼를 결과 버퍼로 복사해야 합니다.
const encoder = device.createCommandEncoder({ label: 'histogram encoder' });
const pass = encoder.beginComputePass();
pass.setPipeline(pipeline);
pass.setBindGroup(0, bindGroup);
pass.dispatchWorkgroups(1);
pass.end();
+ encoder.copyBufferToBuffer(histogramBuffer, 0, resultBuffer, 0, resultBuffer.size);
그런 다음 명령을 실행합니다.
const encoder = device.createCommandEncoder({ label: 'histogram encoder' });
const pass = encoder.beginComputePass();
pass.setPipeline(pipeline);
pass.setBindGroup(0, bindGroup);
pass.dispatchWorkgroups(1);
pass.end();
encoder.copyBufferToBuffer(histogramBuffer, 0, resultBuffer, 0, resultBuffer.size);
+ const commandBuffer = encoder.finish();
+ device.queue.submit([commandBuffer]);
마지막으로 결과 버퍼에서 데이터를 가져와 기존 함수에 전달하여 히스토그램을 그릴 수 있습니다.
await resultBuffer.mapAsync(GPUMapMode.READ); const histogram = new Uint32Array(resultBuffer.getMappedRange()); showImageBitmap(imgBitmap); const numEntries = texture.width * texture.height; drawHistogram(histogram, numEntries); resultBuffer.unmap();
그리고 작동해야 합니다.
결과 타이밍을 측정해보니 JavaScript 버전보다 약 30배 느립니다!!! 😱😱😱 (결과는 다를 수 있습니다).
무슨 일이 일어난 걸까요? 위의 솔루션을 단일 루프로 설계했고 크기가 1인 단일 워크그룹 호출을 사용했습니다. 이는 GPU의 단일 "코어"만 히스토그램을 계산하는 데 사용되었다는 것을 의미합니다. GPU 코어는 일반적으로 CPU 코어만큼 빠르지 않습니다. CPU 코어는 속도를 높이기 위해 많은 추가 회로를 가지고 있습니다. GPU는 대규모 병렬화로 속도를 얻지만 설계를 더 단순하게 유지해야 합니다. 위의 셰이더를 고려하면 병렬화의 이점을 전혀 활용하지 못했습니다.
작은 예제 텍스처를 사용하여 무슨 일이 일어나고 있는지 보여주는 다이어그램입니다.
다이어그램 vs 셰이더 차이점
이 다이어그램은 셰이더를 완벽하게 표현하지 않습니다
- 3개의 빈만 표시하지만 셰이더에는 256개의 빈이 있습니다
- 코드가 단순화되었습니다.
- ▢는 텍셀 색상입니다
- ◯는 휘도로 표현된 빈 선택입니다
- 많은 것들이 약어로 표시됩니다.
wid=workgroup_idgid=global_invocation_idlid=local_invocation_idourTex=ourTexturetexLoad=textureLoad- 등…
이러한 변경 사항은 많은 세부 사항을 표시하기 위한 공간이 제한되어 있기 때문입니다. 이 첫 번째 예제는 단일 호출을 사용하지만, 진행하면서 더 적은 공간에 더 많은 정보를 압축해야 합니다. 다이어그램이 혼란을 주기보다는 이해에 도움이 되기를 바랍니다. 😅
단일 GPU 호출이 CPU보다 느리다는 점을 고려하면 접근 방식을 병렬화할 방법을 찾아야 합니다.
최적화 - 더 많은 호출
아마도 이를 가속화하는 가장 쉽고 명확한 방법은 픽셀당 하나의 워크그룹을 사용하는 것입니다. 위의 코드에는 for 루프가 있습니다.
for (y) {
for (x) {
...
}
}
대신 global_invocation_id를 입력으로 사용하도록 코드를 변경하고
모든 단일 픽셀을 별도의 호출로 처리할 수 있습니다.
셰이더에 필요한 변경 사항은 다음과 같습니다.
@group(0) @binding(0) var<storage, read_write> bins: array<vec4u>;
@group(0) @binding(1) var ourTexture: texture_2d<f32>;
// from: https://www.w3.org/WAI/GL/wiki/Relative_luminance
const kSRGBLuminanceFactors = vec3f(0.2126, 0.7152, 0.0722);
fn srgbLuminance(color: vec3f) -> f32 {
return saturate(dot(color, kSRGBLuminanceFactors));
}
@compute @workgroup_size(1, 1, 1)
-fn cs() {
+fn cs(@builtin(global_invocation_id) global_invocation_id: vec3u) {
- let size = textureDimensions(ourTexture, 0);
let numBins = f32(arrayLength(&bins));
let lastBinIndex = u32(numBins - 1);
- for (var y = 0u; y < size.y; y++) {
- for (var x = 0u; x < size.x; x++) {
- let position = vec2u(x, y);
+ let position = global_invocation_id.xy;
let color = textureLoad(ourTexture, position, 0);
let v = srgbLuminance(color.rgb);
let bin = min(u32(v * numBins), lastBinIndex);
bins[bin] += 1;
- }
- }
}
보시다시피, 루프를 제거하고 대신 @builtin(global_invocation_id) 값을 사용하여
각 워크그룹이 단일 픽셀을 담당하도록 만들었습니다. 이론적으로 이는
모든 픽셀이 병렬로 처리될 수 있다는 것을 의미합니다.
이미지는 2448 × 1505로 거의 370만 픽셀이므로
병렬화의 기회가 많습니다.
필요한 다른 변경 사항은 실제로 픽셀당 하나의 워크그룹을 실행하는 것입니다.
const encoder = device.createCommandEncoder({ label: 'histogram encoder' });
const pass = encoder.beginComputePass();
pass.setPipeline(pipeline);
pass.setBindGroup(0, bindGroup);
- pass.dispatchWorkgroups(1);
+ pass.dispatchWorkgroups(texture.width, texture.height);
pass.end();
여기 실행 중입니다.
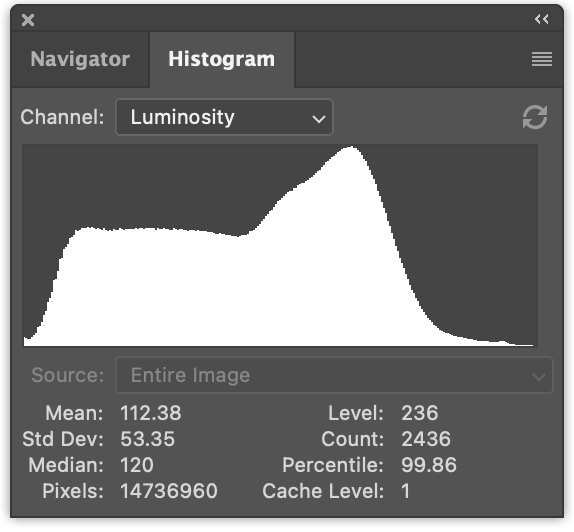
무엇이 잘못되었나요? 이 히스토그램이 이전 히스토그램과 일치하지 않는 이유는 무엇이며 합계가 일치하지 않는 이유는 무엇인가요? 참고: 컴퓨터에 따라 다른 결과를 얻을 수 있습니다. 제 컴퓨터에서는 상단에 이전 버전의 히스토그램이 있고, 하단에 새 버전의 4가지 결과가 있습니다.

새 버전은 일관되지 않은 결과를 얻습니다(적어도 제 컴퓨터에서는).
무슨 일이 일어났나요?
이것은 이전 문서에서 언급한 고전적인 경쟁 조건입니다.
셰이더의 이 줄은
bins[bin] += 1;
실제로 다음과 같이 변환됩니다.
let value = bins[bin]; value = value + 1 bins[bin] = value;
2개 이상의 호출이 병렬로 실행되고
동일한 bin 값을 가질 때 어떻게 될까요?
bin = 1이고 bins[1] = 3인 2개의 호출을 상상해보세요.
병렬로 실행되면 두 호출 모두 3을 로드하고 두 호출 모두 4를 쓰지만,
정답은 5여야 합니다.
| 호출 1 | 호출 2 |
|---|---|
| value = bins[bin] // 3을 로드 | value = bins[bin] // 3을 로드 |
| value = value + 1 // 1을 더함 | value = value + 1 // 1을 더함 |
| bins[bin] = value // 4를 저장 | bins[bin] = value // 4를 저장 |
아래 다이어그램에서 문제를 시각적으로 볼 수 있습니다. 여러 호출이 빈의 현재 값을 가져와서 1을 더하고 다시 넣는 것을 볼 수 있으며, 각각은 다른 호출이 동시에 같은 빈을 읽고 업데이트하고 있다는 것을 모릅니다.
WGSL에는 이 문제를 해결하기 위한 특별한 “원자적(atomic)” 명령이 있습니다.
이 경우 atomicAdd를 사용할 수 있습니다. atomicAdd는 덧셈을 "원자적"으로 만들어
load->add->store의 3가지 작업이 아니라 모든 3가지 작업이 한 번에 “원자적으로” 발생합니다.
이것은 효과적으로 두 개 이상의 호출이 동시에 값을 업데이트하는 것을 방지합니다.
원자 함수는 i32 또는 u32에서만 작동하며 데이터 자체가 atomic 타입이어야 한다는 요구 사항이 있습니다.
셰이더에 대한 변경 사항은 다음과 같습니다.
-@group(0) @binding(0) var<storage, read_write> bins: array<u32>;
+@group(0) @binding(0) var<storage, read_write> bins: array<atomic<u32>>;
@group(0) @binding(1) var ourTexture: texture_2d<f32>;
const kSRGBLuminanceFactors = vec3f(0.2126, 0.7152, 0.0722);
fn srgbLuminance(color: vec3f) -> f32 {
return saturate(dot(color, kSRGBLuminanceFactors));
}
@compute @workgroup_size(1, 1, 1)
fn cs(@builtin(global_invocation_id) global_invocation_id: vec3u) {
let numBins = f32(arrayLength(&bins));
let lastBinIndex = u32(numBins - 1);
let position = global_invocation_id.xy;
let color = textureLoad(ourTexture, position, 0);
let v = srgbLuminance(color.rgb);
let bin = min(u32(v * numBins), lastBinIndex);
- bins[bin] += 1;
+ atomicAdd(&bins[bin], 1u);
}
픽셀당 1개의 워크그룹 호출을 사용하는 컴퓨트 셰이더가 작동합니다!
안타깝게도 새로운 문제가 있습니다. atomicAdd는 효과적으로
다른 호출이 동시에 같은 빈을 업데이트하는 것을 차단해야 합니다.
여기서 문제를 볼 수 있습니다. 아래 다이어그램은 atomicAdd를 3가지 작업으로 표시하지만
호출이 atomicAdd를 수행할 때 “빈을 잠그므로”
다른 호출은 완료될 때까지 기다려야 합니다.
다이어그램에서 호출이 빈을 잠글 때 호출에서 빈까지 빈 색상의 선이 있습니다. 해당 빈이 잠금 해제되기를 기다리는 호출에는 정지 신호 🛑가 표시됩니다.
제 컴퓨터에서는 이 새 버전이 JavaScript보다 약 4배 빠르게 실행되지만 결과는 다를 수 있습니다.
워크그룹
더 빠르게 할 수 있을까요? 이전 문서에서 언급했듯이,
"워크그룹"은 GPU가 수행할 수 있는 가장 작은 작업 단위입니다. 셰이더 모듈을 만들 때
3차원으로 워크그룹의 크기를 정의한 다음 dispatchWorkgroups를 호출하여
이러한 워크그룹을 여러 개 실행합니다.
워크그룹은 내부 스토리지를 공유하고 워크그룹 내에서 해당 스토리지를 조정할 수 있습니다. 이 사실을 어떻게 활용할 수 있을까요?
이렇게 시도해봅시다. 워크그룹 크기를 256x1(워크그룹당 256개의 호출)로 만들겠습니다.
각 호출이 이미지의 256x1 섹션에서 작업하도록 하겠습니다. 이는
Math.ceil(texture.width / 256) * texture.height 총 워크그룹을 갖게 된다는 것을 의미합니다.
2448 × 1505인 이미지의 경우 10 x 1505, 즉 15050개의 워크그룹이 됩니다.
워크그룹 내의 호출이 워크그룹 스토리지를 사용하여 휘도 값을 빈으로 합산하도록 하겠습니다.
마지막으로 워크그룹의 워크그룹 메모리를 자체 "청크"로 복사하겠습니다. 이렇게 하면 다른 워크그룹과 조정할 필요가 없습니다. 완료되면 다른 컴퓨트 셰이더를 실행하여 청크를 합산합니다.
셰이더를 편집해봅시다. 먼저 bins를 storage 타입에서
workgroup 타입으로 변경하여 같은 워크그룹의 호출과만 공유되도록 합니다.
-@group(0) @binding(0) var<storage, read_write> bins: array<atomic<u32>>; +const chunkWidth = 256; +const chunkHeight = 1; +const chunkSize = chunkWidth * chunkHeight; +var<workgroup> bins: array<atomic<u32>, chunkSize>;
위에서 쉽게 변경할 수 있도록 상수를 선언했습니다.
그런 다음 모든 청크를 위한 스토리지가 필요합니다.
+@group(0) @binding(0) var<storage, read_write> chunks: array<array<u32, chunkSize>>;
@group(0) @binding(1) var ourTexture: texture_2d<f32>;
const kSRGBLuminanceFactors = vec3f(0.2126, 0.7152, 0.0722);
fn srgbLuminance(color: vec3f) -> f32 {
return saturate(dot(color, kSRGBLuminanceFactors));
}
상수를 사용하여 워크그룹 크기를 정의할 수 있습니다.
-@compute @workgroup_size(1, 1, 1) +@compute @workgroup_size(chunkWidth, chunkHeight, 1)
빈을 증가시키는 주요 부분은 이전 셰이더와 매우 유사합니다.
fn cs(@builtin(global_invocation_id) global_invocation_id: vec3u) {
let size = textureDimensions(ourTexture, 0);
let position = global_invocation_id.xy;
+ if (all(position < size)) {
- let numBins = f32(arrayLength(&bins));
+ let numBins = f32(chunkSize);
let lastBinIndex = u32(numBins - 1);
let color = textureLoad(ourTexture, position, 0);
let v = srgbLuminance(color.rgb);
let bin = min(u32(v * numBins), lastBinIndex);
atomicAdd(&bins[bin], 1u);
}
청크 크기가 셰이더에 하드코딩되어 있기 때문에 텍스처 외부의
픽셀에서 작업하지 않도록 하겠습니다. 예를 들어 이미지가 300픽셀
너비인 경우, 첫 번째 워크그룹은 픽셀 0에서 255까지 작업합니다. 두 번째 워크그룹은
픽셀 256에서 511까지 작업합니다. 하지만 픽셀 299까지만 작업하면 됩니다.
이것이 if(all(position < size))가 하는 일입니다. position과 size 모두
vec2u이므로 position < size는 2개의 부울 값을 생성하며 이는 vec2<bool>입니다.
all 함수는 모든 입력이 true이면 true를 반환합니다. 따라서 코드는
position.x < size.x이고 position.y < size.y인 경우에만 if 내부로 들어갑니다.
numBins의 경우, 청크 크기에 대해 정의한 만큼의 빈이 있습니다.
var<storage>에 대해 했던 것처럼 버퍼를 전달하지 않기 때문에 더 이상 크기를 조회할 수 없습니다.
크기는 셰이더 모듈을 만들 때 정의됩니다.
마지막으로 셰이더의 가장 다른 부분입니다.
workgroupBarrier(); let chunksAcross = (size.x + chunkWidth - 1) / chunkWidth; let chunkDim = vec2u(chunkWidth, chunkHeight); let chunkPos = global_invocation_id.xy / chunkDim; let chunk = chunkPos.y * chunksAcross + chunkPos.x; let binPos = global_invocation_id.xy % chunkDim; let bin = binPos.y * chunkWidth + binPos.x; chunks[chunk][bin] = atomicLoad(&bins[bin]); }
이 부분은 각 호출이 하나의 빈을 특정 청크의 해당 빈으로 복사하도록 합니다.
청크는 이 워크그룹이 작업하는 청크입니다.
일부 계산은 global_invocation_id를
chunkPos와 binPos 모두로 변환하기 위한 것입니다. 이러한 값은 효과적으로
workgroup_id와 local_invocation_id이므로 이 코드를 단순화할 수 있습니다.
workgroupBarrier(); let chunksAcross = (size.x + chunkWidth - 1) / chunkWidth; let chunk = workgroup_id.y * chunksAcross + workgroup_id.x; let bin = local_invocation_id.y * chunkWidth + local_invocation_id.x; chunks[chunk][bin] = atomicLoad(&bins[bin]); }
그런 다음 workgroup_id와 local_invocation_id를 셰이더 함수의 입력으로 추가해야 합니다.
-fn cs(@builtin(global_invocation_id) global_invocation_id: vec3u) {
+fn cs(
+ @builtin(global_invocation_id) global_invocation_id: vec3u,
+ @builtin(workgroup_id) workgroup_id: vec3u,
+ @builtin(local_invocation_id) local_invocation_id: vec3u,
+) {
...
workgroupBarrier
workgroupBarrier()는 효과적으로 "이 워크그룹의 모든 호출이 이 지점에 도달할 때까지 여기서 멈춥니다"라고 말합니다.
각 호출이 bins의 다른 요소를 업데이트하지만, 나중에 각 호출이
bins에서 하나의 요소만 chunks의 해당 요소로 복사하므로 다른 모든 호출이 완료되었는지 확인해야 하기 때문에 필요합니다.
다르게 말하자면, 텍스처에서 읽는 색상에 따라 모든 호출이 bins의 모든 요소를 atomicAdd할 수 있습니다.
하지만 local_invocation_id = 3,0인 호출만 bin[3]을 chunks[chunk][3]으로 복사하므로
다른 모든 호출이 bin[3]을 업데이트할 기회를 가질 때까지 기다려야 합니다.
모두 합치면 새로운 셰이더는 다음과 같습니다.
const chunkWidth = 256;
const chunkHeight = 1;
const chunkSize = chunkWidth * chunkHeight;
var<workgroup> bins: array<atomic<u32>, chunkSize>;
@group(0) @binding(0) var<storage, read_write> chunks: array<array<u32, chunkSize>>;
@group(0) @binding(1) var ourTexture: texture_2d<f32>;
const kSRGBLuminanceFactors = vec3f(0.2126, 0.7152, 0.0722);
fn srgbLuminance(color: vec3f) -> f32 {
return saturate(dot(color, kSRGBLuminanceFactors));
}
@compute @workgroup_size(chunkWidth, chunkHeight, 1)
fn cs(
@builtin(global_invocation_id) global_invocation_id: vec3u,
@builtin(workgroup_id) workgroup_id: vec3u,
@builtin(local_invocation_id) local_invocation_id: vec3u,
) {
let size = textureDimensions(ourTexture, 0);
let position = global_invocation_id.xy;
if (all(position < size)) {
let numBins = f32(chunkSize);
let lastBinIndex = u32(numBins - 1);
let color = textureLoad(ourTexture, position, 0);
let v = srgbLuminance(color.rgb);
let bin = min(u32(v * numBins), lastBinIndex);
atomicAdd(&bins[bin], 1u);
}
workgroupBarrier();
let chunksAcross = (size.x + chunkWidth - 1) / chunkWidth;
let chunk = workgroup_id.y * chunksAcross + workgroup_id.x;
let bin = local_invocation_id.y * chunkWidth + local_invocation_id.x;
chunks[chunk][bin] = atomicLoad(&bins[bin]);
}
한 가지 더 할 수 있는 것은 chunkWidth와 chunkHeight를 하드코딩하는 대신
JavaScript에서 다음과 같이 전달할 수 있습니다.
+ const k = {
+ chunkWidth: 256,
+ chunkHeight: 1,
+ };
+ const sharedConstants = Object.entries(k)
+ .map(([k, v]) => `const ${k} = ${v};`)
+ .join('\n');
const histogramChunkModule = device.createShaderModule({
label: 'histogram chunk shader',
code: /* wgsl */ `
- const chunkWidth = 256;
- const chunkHeight = 1;
+ ${sharedConstants}
const chunkSize = chunkWidth * chunkHeight;
var<workgroup> bins: array<atomic<u32>, chunkSize>;
@group(0) @binding(0) var<storage, read_write> chunks: array<array<u32, chunkSize>>;
@group(0) @binding(1) var ourTexture: texture_2d<f32>;
...
`,
});
이 셰이더를 실행하면 다음과 같이 작동합니다.
위에서 볼 수 있듯이, 각 워크그룹은 한 청크 분량의 픽셀을 읽고
빈을 적절히 업데이트합니다. 이전과 마찬가지로, 2개의 호출이 같은
빈을 업데이트해야 하는 경우 하나는 기다려야 합니다 🛑. 그 후 모두
workgroupBarrier 🚧에서 서로를 기다립니다. 그 후 각 호출은 담당하는 빈을
작업 중인 청크의 해당 빈으로 복사합니다.
청크 합산하기
이제 모든 픽셀 휘도 값이 계산되었지만 빈을 합산하여 답을 얻어야 합니다. 이를 수행하는 컴퓨트 셰이더를 작성해봅시다. 빈당 하나의 호출을 수행할 수 있습니다. 각 호출은 각 청크의 같은 빈에서 모든 값을 더한 다음 결과를 첫 번째 청크에 씁니다.
코드는 다음과 같습니다.
const chunkWidth = 256;
const chunkHeight = 1;
const chunkSize = chunkWidth * chunkHeight;
@group(0) @binding(0) var<storage, read_write> chunks: array<array<u32, chunkSize>>;
@compute @workgroup_size(chunkSize, 1, 1)
fn cs(@builtin(local_invocation_id) local_invocation_id: vec3u) {
var sum = u32(0);
let numChunks = arrayLength(&chunks);
for (var i = 0u; i < numChunks; i++) {
sum += chunks[i][local_invocation_id.x];
}
chunks[0][local_invocation_id.x] = sum;
}
그리고 이전과 마찬가지로 chunkWidth와 chunkHeight를 주입할 수 있습니다.
const chunkSumModule = device.createShaderModule({
label: 'chunk sum shader',
code: /* wgsl */ `
* ${sharedConstants}
const chunkSize = chunkWidth * chunkHeight;
@group(0) @binding(0) var<storage, read_write> chunks: array<array<u32, chunkSize>>;
@compute @workgroup_size(chunkSize, 1, 1)
...
}
`,
});
이 셰이더는 효과적으로 다음과 같이 작동합니다.
이제 이 2개의 셰이더가 있으니 코드를 업데이트하여 사용해봅시다. 두 셰이더 모두에 대한 파이프라인을 만들어야 합니다.
- const pipeline = device.createComputePipeline({
- label: 'histogram',
- layout: 'auto',
- compute: {
- module,
-- },
- });
+ const histogramChunkPipeline = device.createComputePipeline({
+ label: 'histogram',
+ layout: 'auto',
+ compute: {
+ module: histogramChunkModule,
++ },
+ });
+
+ const chunkSumPipeline = device.createComputePipeline({
+ label: 'chunk sum',
+ layout: 'auto',
+ compute: {
+ module: chunkSumModule,
++ },
+ });
전체 이미지를 커버할 수 있을 만큼 큰 스토리지 버퍼를 만들어야 하므로 전체 이미지를 커버하는 데 필요한 청크 수를 계산합니다.
const imgBitmap = await loadImageBitmap('resources/images/pexels-francesco-ungaro-96938-mid.jpg');
const texture = createTextureFromSource(device, imgBitmap);
- const numBins = 256;
- const histogramBuffer = device.createBuffer({
- size: numBins * 4, // 256 entries * 4 bytes per (u32)
- usage: GPUBufferUsage.STORAGE | GPUBufferUsage.COPY_SRC,
- });
+ const chunkSize = k.chunkWidth * k.chunkHeight;
+ const chunksAcross = Math.ceil(texture.width / k.chunkWidth);
+ const chunksDown = Math.ceil(texture.height / k.chunkHeight);
+ const numChunks = chunksAcross * chunksDown;
+ const chunksBuffer = device.createBuffer({
+ size: numChunks * chunkSize * 4, // 4 bytes per (u32)
+ usage: GPUBufferUsage.STORAGE | GPUBufferUsage.COPY_SRC,
+ });
결과를 읽기 위한 결과 버퍼가 여전히 필요하지만 더 이상 이전 버퍼와 같은 크기가 아닙니다.
const resultBuffer = device.createBuffer({
- size: histogramBuffer.size,
+ size: chunkSize * 4, // 4 bytes per (u32)
usage: GPUBufferUsage.COPY_DST | GPUBufferUsage.MAP_READ,
});
각 패스에 대한 바인드그룹이 필요합니다. 하나는 텍스처와 청크를 첫 번째 셰이더에 전달하고 다른 하나는 청크를 두 번째 셰이더에 전달합니다.
- const bindGroup = device.createBindGroup({
+ const histogramBindGroup = device.createBindGroup({
label: 'histogram bindGroup',
layout: histogramChunkPipeline.getBindGroupLayout(0),
entries: [
- { binding: 0, resource: histogramBuffer },
+ { binding: 0, resource: chunksBuffer },
{ binding: 1, resource: texture },
],
});
const chunkSumBindGroup = device.createBindGroup({
label: 'sum bindGroup',
layout: chunkSumPipeline.getBindGroupLayout(0),
entries: [
{ binding: 0, resource: chunksBuffer },
],
});
마지막으로 셰이더를 실행할 수 있습니다. 먼저 픽셀을 읽고 빈으로 정렬하는 부분, 각 청크에 대해 하나의 워크그룹을 디스패치합니다.
const encoder = device.createCommandEncoder({ label: 'histogram encoder' });
const pass = encoder.beginComputePass();
+ // 각 영역에 대한 히스토그램 생성
- pass.setPipeline(pipeline);
- pass.setBindGroup(0, bindGroup);
- pass.dispatchWorkgroups(texture.width, texture.height);
+ pass.setPipeline(histogramChunkPipeline);
+ pass.setBindGroup(0, histogramBindGroup);
+ pass.dispatchWorkgroups(chunksAcross, chunksDown);
그런 다음 청크를 합산하는 셰이더를 실행해야 합니다. 빈당 1개의 호출을 사용하는 1개의 워크그룹입니다(256개의 호출).
+ // 영역 합산 + pass.setPipeline(chunkSumPipeline); + pass.setBindGroup(0, chunkSumBindGroup); + pass.dispatchWorkgroups(1);
나머지 코드는 동일합니다.
제 컴퓨터에서 타이밍을 측정해보니 첫 번째 셰이더가 0.2ms에 실행됩니다! 전체 이미지를 읽고 모든 청크를 매우 빠르게 채웠습니다!
안타깝게도 청크를 합산하는 부분은 훨씬 오래 걸렸습니다. 11ms 이전 셰이더보다 느립니다!
다른 컴퓨터에서는 이전 솔루션이 4.4ms였고 새로운 것은 1.7ms였으므로 완전한 손실은 아니었습니다.
더 잘할 수 있을까요?
리듀스
위의 솔루션은 단일 워크그룹을 사용했습니다. 256개의 호출이 있지만 최신 GPU에는 수천 개의 코어가 있고 우리는 그 중 256개만 사용하고 있습니다.
리듀싱이라고 불리는 기술을 여기서 시도해볼 수 있습니다. 각 워크그룹이 2개의 청크만 추가하도록 하여 결과를 처음 2개의 청크 중 첫 번째에 씁니다. 이렇게 하면 1000개의 청크가 있으면 500개의 워크그룹을 사용할 수 있습니다. 훨씬 더 많은 병렬화입니다. 500개의 청크가 250개로, 250 -> 125, 125 -> 63 등으로 1개의 청크로 줄일 때까지 프로세스를 반복합니다.
하나의 셰이더만 사용할 수 있으며 청크를 하나의 청크로 줄이기 위해 스트라이드를 전달하기만 하면 됩니다. 스트라이드는 합산하는 두 번째 청크로 이동하기 위해 진행해야 하는 청크 수입니다. 스트라이드 1을 전달하면 인접한 청크를 합산합니다. 스트라이드 2를 전달하면 다른 모든 청크를 합산합니다. 등등…
셰이더에 대한 변경 사항은 다음과 같습니다.
const chunkSumModule = device.createShaderModule({
label: 'chunk sum shader',
code: /* wgsl */ `
${sharedConstants}
const chunkSize = chunkWidth * chunkHeight;
+ struct Uniforms {
+ stride: u32,
+ };
@group(0) @binding(0) var<storage, read_write> chunks: array<array<vec4u, chunkSize>>;
+ @group(0) @binding(1) var<uniform> uni: Uniforms;
@compute @workgroup_size(chunkSize, 1, 1) fn cs(
@builtin(local_invocation_id) local_invocation_id: vec3u,
@builtin(workgroup_id) workgroup_id: vec3u,
) {
- var sum = u32(0);
- let numChunks = arrayLength(&chunks);
- for (var i = 0u; i < numChunks; i++) {
- sum += chunks[i][local_invocation_id.x];
- }
- chunks[0][local_invocation_id.x] = sum;
+ let chunk0 = workgroup_id.x * uni.stride * 2;
+ let chunk1 = chunk0 + uni.stride;
+
+ let sum = chunks[chunk0][local_invocation_id.x] +
+ chunks[chunk1][local_invocation_id.x];
+ chunks[chunk0][local_invocation_id.x] = sum;
}
`,
});
위에서 볼 수 있듯이, 유니폼으로 전달하는 workgroup_id.x와 uni.stride를 기반으로
chunk0과 chunk1을 계산합니다. 그런 다음 2개의 청크에서 2개의 빈을 더하고
첫 번째에 다시 저장합니다.
올바른 호출 수와 스트라이드 설정으로 실행하면 다음과 같이 작동합니다. 참고: 어두워진 청크는 더 이상 사용되지 않는 청크입니다.
이 새로운 코드를 작동시키려면 각 스트라이드 값에 대한 유니폼 버퍼와 바인드그룹을 추가해야 합니다.
const sumBindGroups = [];
const numSteps = Math.ceil(Math.log2(numChunks));
for (let i = 0; i < numSteps; ++i) {
const stride = 2 ** i;
const uniformBuffer = device.createBuffer({
size: 4,
usage: GPUBufferUsage.UNIFORM,
mappedAtCreation: true,
});
new Uint32Array(uniformBuffer.getMappedRange()).set([stride]);
uniformBuffer.unmap();
const chunkSumBindGroup = device.createBindGroup({
layout: chunkSumPipeline.getBindGroupLayout(0),
entries: [
{ binding: 0, resource: chunksBuffer },
{ binding: 1, resource: uniformBuffer },
],
});
sumBindGroups.push(chunkSumBindGroup);
}
그런 다음 1개의 청크로 줄일 때까지 올바른 디스패치 수로 이것들을 호출하기만 하면 됩니다.
- // 영역 합산
- pass.setPipeline(chunkSumPipeline);
- pass.setBindGroup(0, chunkSumBindGroup);
- pass.dispatchWorkgroups(1);
+ // 청크 리듀스
+ const pass = encoder.beginComputePass();
+ pass.setPipeline(chunkSumPipeline);
+ let chunksLeft = numChunks;
+ sumBindGroups.forEach(bindGroup => {
+ pass.setBindGroup(0, bindGroup);
+ const dispatchCount = Math.floor(chunksLeft / 2);
+ chunksLeft -= dispatchCount;
+ pass.dispatchWorkgroups(dispatchCount);
+ });
이 버전의 타이밍을 측정해보니 테스트한 두 컴퓨터 모두에서 1ms 미만이 나왔습니다! 🎉🚀
다양한 컴퓨터의 타이밍은 다음과 같습니다.
히스토그램을 계산하는 더 빠른 방법이 있을 수 있습니다. 다른 청크 크기를 시도하는 것도 좋을 수 있습니다. 256x1보다 16x16이 더 나을 수도 있습니다. 또한 어느 시점에서 WebGPU는 서브그룹을 지원할 가능성이 높으며 이는 또 다른 전체 주제이자 더 많은 최적화를 위한 영역입니다.
이 예제들이 컴퓨트 셰이더를 작성하고 최적화하는 방법에 대한 아이디어를 제공했기를 바랍니다. 요점은 다음과 같습니다.
-
GPU가 제공하는 모든 병렬화를 사용하는 방법을 찾으세요
-
경쟁 조건을 인식하세요
-
var<workgroup>를 사용하여 워크그룹의 모든 호출 간에 공유되는 스토리지를 만드세요 -
호출 간 조정이 덜 필요한 알고리즘을 설계하세요.
-
조정이 필요한 경우 원자 연산과
workgroupBarrier가 솔루션이 될 수 있습니다.우리는 이 부분에서 그럭저럭 했습니다. 워크그룹 메모리에서 청크를 계산할 때 여전히 충돌이 있으며
atomicAdd를 통해 해결했지만 워크그룹의bins에서chunks로 복사할 때는 충돌이 없으며chunks를 하나의 최종 결과로 줄일 때도 충돌이 없습니다.
하나 더
-
GPU가 빠르다고 가정하지 마세요.
GPU의 개별 코어는 그다지 빠르지 않다는 것을 배웠습니다. 모든 속도는 병렬화에서 나오므로 병렬 솔루션을 설계해야 합니다.
다음 문서에서는 이것들을 약간 조정하고 JavaScript로 가져오는 대신 GPU를 사용하여 결과를 그래프로 그리도록 변경하겠습니다. 또한 이미지 히스토그램을 생성한 것을 기반으로 실시간 비디오 조정을 시도해보겠습니다.