WebGPU 计算着色器 - 图像直方图
本文是计算着色器基础文章的续篇。
这将是一篇较长的两篇文章,我们会通过多个步骤来优化。这个优化会让速度更快,但结果不会改变,所以每一步看起来都与上一步相同。
此外,我们会提到速度和计时,但如果在示例中添加计时代码,文章和示例会变得更长,所以我们把计时相关的内容留到另一篇文章,在这些文章中我只提及我自己的计时结果,并提供一些可运行的示例。希望这篇文章能为你提供一个编写计算着色器的示例。
图像直方图是指将图像中所有像素按其像素值或其某种度量值进行求和汇总。
例如,这张 6x7 的图像
它有这些颜色。
对于每种颜色,我们可以计算其亮度值(有多亮)。在网上查找后,我找到了这个公式
// 返回 0 到 1 之间的亮度值。
// 其中 r, g, b 的取值范围都是 0 到 1。
function srgbLuminance(r, g, b) {
// 来源: https://www.w3.org/WAI/GL/wiki/Relative_luminance
return r * 0.2126 +
g * 0.7152 +
b * 0.0722;
}
使用这个公式,我们可以将每个值转换为亮度等级
我们可以设定若干个"箱子"(bin)。让我们设定 3 个箱子。 然后将这些亮度值量化,使它们分别落入某个"箱子",并统计每个箱子中的像素数量。
最后,我们可以将箱子的值绘制成图表
图表显示,暗部像素(🟦 18)比中等亮度的像素(🟥 16)多,而亮部像素(🟨 8)更少。仅有 3 个箱子还不太有趣。但如果我们拿一张这样的照片

统计像素的亮度值,将其分为比如 256 个箱子并绘图,我们会得到类似这样的结果
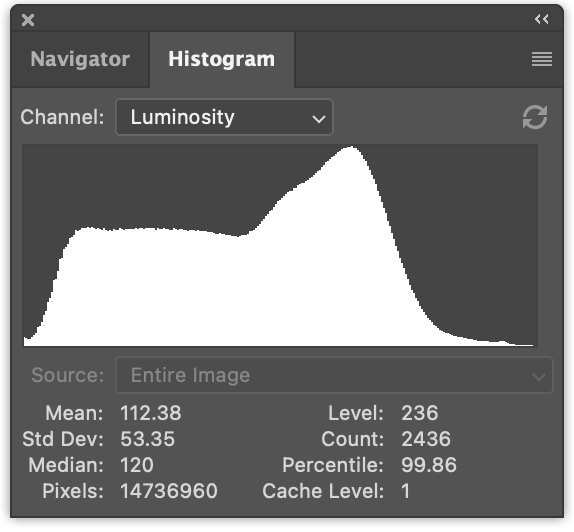
计算图像直方图其实很简单。让我们先用 JavaScript 来实现。
让我们编写一个函数,给定一个 ImageData 对象,生成直方图。
function computeHistogram(numBins, imgData) {
const {width, height, data} = imgData;
const bins = new Array(numBins).fill(0);
for (let y = 0; y < height; ++y) {
for (let x = 0; x < width; ++x) {
const offset = (y * width + x) * 4;
const r = data[offset + 0] / 255;
const g = data[offset + 1] / 255;
const b = data[offset + 2] / 255;
const v = srgbLuminance(r, g, b);
const bin = Math.min(numBins - 1, v * numBins) | 0;
++bins[bin];
}
}
return bins;
}
如上所示,我们遍历每个像素。从图像中提取 r、g、b 值,计算亮度值,然后将其转换为箱子索引并增加该箱子的计数。
一旦有了这些数据,我们就可以绘制它。主绘图函数遍历每个箱子,绘制一条高度为 该箱子值 * 缩放比例 * 画布高度 的竖线。
ctx.fillStyle = '#fff';
for (let x = 0; x < numBins; ++x) {
const v = histogram[x] * scale * height;
ctx.fillRect(x, height - v, 1, v);
}
选择缩放比例似乎纯属个人选择。如果你有好的公式来选择缩放比例,请留言。😅 通过在网上搜索,我得出了这个缩放公式。
const numBins = histogram.length; const max = Math.max(...histogram); const scale = Math.max(1 / max, 0.2 * numBins / numEntries);
其中 numEntries 是图像中的像素总数(即 width * height),
基本上我们是试图让最大值对应的箱子刚好触及图表顶部,但如果该箱子太大,
则使用一个比例来产生看起来更舒适的图表。
综合以上内容,我们创建一个 2D 画布并绘制
function drawHistogram(histogram, numEntries, height = 100) {
const numBins = histogram.length;
const max = Math.max(...histogram);
const scale = Math.max(1 / max, 0.2 * numBins / numEntries);
const canvas = document.createElement('canvas');
canvas.width = numBins;
canvas.height = height;
document.body.appendChild(canvas);
const ctx = canvas.getContext('2d');
ctx.fillStyle = '#fff';
for (let x = 0; x < numBins; ++x) {
const v = histogram[x] * scale * height;
ctx.fillRect(x, height - v, 1, v);
}
}
现在我们需要加载一张图片。我们将使用在加载图片的文章中编写的代码。
async function main() {
const imgBitmap = await loadImageBitmap('resources/images/pexels-francesco-ungaro-96938-mid.jpg');
我们需要从图像中获取数据。为此,我们可以将图像绘制到 2D 画布上,然后使用 getImageData。
function getImageData(img) {
const canvas = document.createElement('canvas');
// 让画布与图像尺寸相同
canvas.width = img.naturalWidth;
canvas.height = img.naturalHeight;
const ctx = canvas.getContext('2d');
ctx.drawImage(img, 0, 0);
return ctx.getImageData(0, 0, canvas.width, canvas.height);
}
我们还要编写一个函数来显示 ImageBitmap
function showImageBitmap(imageBitmap) {
const canvas = document.createElement('canvas');
canvas.width = imageBitmap.width;
canvas.height = imageBitmap.height;
const bm = canvas.getContext('bitmaprenderer');
bm.transferFromImageBitmap(imageBitmap);
document.body.appendChild(canvas);
}
让我们添加一些 CSS,使图片不会显示得过大,并给它一个背景色,这样就不需要自己绘制背景了。
canvas {
display: block;
max-width: 256px;
border: 1px solid #888;
background-color: #333;
}
然后我们只需要调用上面编写的函数即可。
async function main() {
const imgBitmap = await loadImageBitmap('resources/images/pexels-francesco-ungaro-96938-mid.jpg');
const imgData = getImageData(imgBitmap);
const numBins = 256;
const histogram = computeHistogram(numBins, imgData);
showImageBitmap(imgBitmap);
const numEntries = imgData.width * imgData.height;
drawHistogram(histogram, numEntries);
}
这就是图像直方图。
希望你能轻松理解 JavaScript 代码在做什么。接下来我们把它转换成 WebGPU!
在 GPU 上计算直方图
让我们从最直接的方案开始。我们将直接把 JavaScript 的 computeHistogram 函数转换为 WGSL。
亮度函数非常简单。再次回顾 JavaScript 版本
// 返回 0 到 1 之间的亮度值。
// 其中 r, g, b 的取值范围都是 0 到 1。
function srgbLuminance(r, g, b) {
// 来源: https://www.w3.org/WAI/GL/wiki/Relative_luminance
return r * 0.2126 +
g * 0.7152 +
b * 0.0722;
}
对应的 WGSL 版本如下
// 来源: https://www.w3.org/WAI/GL/wiki/Relative_luminance
const kSRGBLuminanceFactors = vec3f(0.2126, 0.7152, 0.0722);
fn srgbLuminance(color: vec3f) -> f32 {
return saturate(dot(color, kSRGBLuminanceFactors));
}
dot 函数是"点积"的缩写,它将一个向量的每个元素与另一个向量对应位置的元素相乘,然后求和。对于上面的 vec3f,可以定义为
fn dot(a: vec3f, b: vec3f) -> f32 {
return a.x * b.x + a.y * b.y + a.z * b.z;
}
这与我们在 JavaScript 中的做法一致。主要区别在于在 WGSL 中,我们传入的是 vec3f 类型的颜色,而不是单独的通道。
计算直方图的主要部分如下,再次回顾 JavaScript 版本
function computeHistogram(numBins, imgData) {
const {width, height, data} = imgData;
const bins = new Array(numBins).fill(0);
for (let y = 0; y < height; ++y) {
for (let x = 0; x < width; ++x) {
const offset = (y * width + x) * 4;
const r = data[offset + 0] / 255;
const g = data[offset + 1] / 255;
const b = data[offset + 2] / 255;
const v = srgbLuminance(r, g, b);
const bin = Math.min(numBins - 1, v * numBins) | 0;
++bins[bin];
}
}
return bins;
}
对应的 WGSL 版本
@group(0) @binding(0) var<storage, read_write> bins: array<u32>;
@group(0) @binding(1) var ourTexture: texture_2d<f32>;
// 来源: https://www.w3.org/WAI/GL/wiki/Relative_luminance
const kSRGBLuminanceFactors = vec3f(0.2126, 0.7152, 0.0722);
fn srgbLuminance(color: vec3f) -> f32 {
return saturate(dot(color, kSRGBLuminanceFactors));
}
@compute @workgroup_size(1) fn cs() {
let size = textureDimensions(ourTexture, 0);
let numBins = f32(arrayLength(&bins));
let lastBinIndex = u32(numBins - 1);
for (var y = 0u; y < size.y; y++) {
for (var x = 0u; x < size.x; x++) {
let position = vec2u(x, y);
let color = textureLoad(ourTexture, position, 0);
let v = srgbLuminance(color.rgb);
let bin = min(u32(v * numBins), lastBinIndex);
bins[bin] += 1;
}
}
}
如上,变化不大。在 JavaScript 中我们从 imgData 获取 data、width 和 height。
在 WGSL 中我们通过将纹理传入 textureDimensions 函数来获取宽高。
let size = textureDimensions(ourTexture, 0);
textureDimensions 接收一个纹理和一个 mip 级别(上面的 0),返回该纹理在该 mip 级别下的尺寸。
我们遍历纹理的所有像素,就像在 JavaScript 中一样。
for (var y = 0u; y < size.y; y++) {
for (var x = 0u; x < size.x; x++) {
我们调用 textureLoad 从纹理中获取颜色。
let position = vec2u(x, y);
let color = textureLoad(ourTexture, position, 0);
textureLoad 从纹理的单个 mip 级别中返回单个纹理像素。
它接收一个纹理、一个 vec2u 纹理坐标位置和一个 mip 级别(0)。
我们计算亮度值,将其转换为箱子索引,并增加该箱子的计数。
let position = vec2u(x, y);
let color = textureLoad(ourTexture, position, 0);
+ let v = srgbLuminance(color.rgb);
+ let bin = min(u32(v * numBins), lastBinIndex);
+ bins[bin] += 1;
现在我们有了计算着色器,来使用它吧
我们使用非常标准的初始化代码
async function main() {
const adapter = await navigator.gpu?.requestAdapter();
const device = await adapter?.requestDevice();
if (!device) {
fail('need a browser that supports WebGPU');
return;
}
然后我们创建着色器
const module = device.createShaderModule({
label: 'histogram shader',
code: /* wgsl */ `
@group(0) @binding(0) var<storage, read_write> bins: array<u32>;
@group(0) @binding(1) var ourTexture: texture_2d<f32>;
// 来源: https://www.w3.org/WAI/GL/wiki/Relative_luminance
const kSRGBLuminanceFactors = vec3f(0.2126, 0.7152, 0.0722);
fn srgbLuminance(color: vec3f) -> f32 {
return saturate(dot(color, kSRGBLuminanceFactors));
}
@compute @workgroup_size(1) fn cs() {
let size = textureDimensions(ourTexture, 0);
let numBins = f32(arrayLength(&bins));
let lastBinIndex = u32(numBins - 1);
for (var y = 0u; y < size.y; y++) {
for (var x = 0u; x < size.x; x++) {
let position = vec2u(x, y);
let color = textureLoad(ourTexture, position, 0);
let v = srgbLuminance(color.rgb);
let bin = min(u32(v * numBins), lastBinIndex);
bins[bin] += 1;
}
}
}
`,
});
我们创建一个计算管线来运行着色器
const pipeline = device.createComputePipeline({
label: 'histogram',
layout: 'auto',
compute: {
module,
},
});
加载图片后,我们需要创建一个纹理并将数据复制到其中。
我们将使用在将图片加载到纹理的文章中编写的 createTextureFromSource 函数。
const imgBitmap = await loadImageBitmap('resources/images/pexels-francesco-ungaro-96938-mid.jpg');
const texture = createTextureFromSource(device, imgBitmap);
我们需要为着色器创建一个存储缓冲区,用于累计颜色值
const numBins = 256;
const histogramBuffer = device.createBuffer({
size: numBins * 4, // 256 个条目 * 每个 (u32) 4 字节
usage: GPUBufferUsage.STORAGE | GPUBufferUsage.COPY_SRC,
});
以及一个用于获取结果以便绘图的缓冲区
const resultBuffer = device.createBuffer({
size: histogramBuffer.size,
usage: GPUBufferUsage.COPY_DST | GPUBufferUsage.MAP_READ,
});
我们需要创建一个绑定组,将纹理和直方图缓冲区传递给管线
const bindGroup = device.createBindGroup({
label: 'histogram bindGroup',
layout: pipeline.getBindGroupLayout(0),
entries: [
{ binding: 0, resource: histogramBuffer },
{ binding: 1, resource: texture },
],
});
现在我们可以设置运行计算着色器的命令
const encoder = device.createCommandEncoder({ label: 'histogram encoder' });
const pass = encoder.beginComputePass();
pass.setPipeline(pipeline);
pass.setBindGroup(0, bindGroup);
pass.dispatchWorkgroups(1);
pass.end();
我们需要将直方图缓冲区复制到结果缓冲区
const encoder = device.createCommandEncoder({ label: 'histogram encoder' });
const pass = encoder.beginComputePass();
pass.setPipeline(pipeline);
pass.setBindGroup(0, bindGroup);
pass.dispatchWorkgroups(1);
pass.end();
+ encoder.copyBufferToBuffer(histogramBuffer, 0, resultBuffer, 0, resultBuffer.size);
然后执行命令
const encoder = device.createCommandEncoder({ label: 'histogram encoder' });
const pass = encoder.beginComputePass();
pass.setPipeline(pipeline);
pass.setBindGroup(0, bindGroup);
pass.dispatchWorkgroups(1);
pass.end();
encoder.copyBufferToBuffer(histogramBuffer, 0, resultBuffer, 0, resultBuffer.size);
+ const commandBuffer = encoder.finish();
+ device.queue.submit([commandBuffer]);
最后,我们可以从结果缓冲区获取数据,并将其传递给现有函数绘制直方图
await resultBuffer.mapAsync(GPUMapMode.READ); const histogram = new Uint32Array(resultBuffer.getMappedRange()); showImageBitmap(imgBitmap); const numEntries = texture.width * texture.height; drawHistogram(histogram, numEntries); resultBuffer.unmap();
应该可以工作了
计时结果显示,这比 JavaScript 版本慢了约 30 倍!!! 😱😱😱(实际结果因机器而异)。
为什么会这样?我们在上面的设计中使用了单个循环,并使用大小为 1 的单个工作组调用。 这意味着只使用了 GPU 的一个"核心"来计算直方图。GPU 核心通常不如 CPU 核心快。 CPU 核心有大量额外的电路来尝试加速。GPU 的速度来自于大规模并行化,但需要保持设计更简单。 鉴于我们上面的着色器没有利用任何并行化,这种结果是必然的。
下面是用我们的小示例纹理来展示正在发生的事情的图表。
图表与着色器代码的差异
这些图表并不是着色器的完美表示
- 它们只显示 3 个箱子,而我们的着色器有 256 个箱子
- 代码被简化了。
- ▢ 是纹理像素颜色
- ◯ 是以亮度表示的箱子选择
- 许多内容被缩写。
wid=workgroup_idgid=global_invocation_idlid=local_invocation_idourTex=ourTexturetexLoad=textureLoad- 等等…
做出这些改动的原因是展示空间有限,需要展示更多细节。随着我们逐步深入到第一个示例只使用单个调用的情况,我们需要用更少的空间塞入更多信息。 希望这些图表有助于理解,而不是让人更困惑。 😅
鉴于单个 GPU 调用比 CPU 慢,我们需要找到一种并行化方案。
优化 - 更多调用
最简单和最明显的加速方法是为每个像素使用一个工作组。在上面的代码中,我们有一个 for 循环
for (y) {
for (x) {
...
}
}
我们可以改为使用 global_invocation_id 作为输入,然后让每个单独的调用处理每个像素。
下面是着色器需要的改动
@group(0) @binding(0) var<storage, read_write> bins: array<vec4u>;
@group(0) @binding(1) var ourTexture: texture_2d<f32>;
// 来源: https://www.w3.org/WAI/GL/wiki/Relative_luminance
const kSRGBLuminanceFactors = vec3f(0.2126, 0.7152, 0.0722);
fn srgbLuminance(color: vec3f) -> f32 {
return saturate(dot(color, kSRGBLuminanceFactors));
}
@compute @workgroup_size(1, 1, 1)
-fn cs() {
+fn cs(@builtin(global_invocation_id) global_invocation_id: vec3u) {
- let size = textureDimensions(ourTexture, 0);
let numBins = f32(arrayLength(&bins));
let lastBinIndex = u32(numBins - 1);
- for (var y = 0u; y < size.y; y++) {
- for (var x = 0u; x < size.x; x++) {
- let position = vec2u(x, y);
+ let position = global_invocation_id.xy;
let color = textureLoad(ourTexture, position, 0);
let v = srgbLuminance(color.rgb);
let bin = min(u32(v * numBins), lastBinIndex);
bins[bin] += 1;
- }
- }
}
如你所见,我们去掉了循环,改为使用 @builtin(global_invocation_id) 值,
让每个工作组负责处理一个像素。理论上所有像素都可以并行处理。
我们的图像是 2448 × 1505,几乎有 370 万像素,所以有很多可以并行的机会。
唯一还需要改动的是实际为每个像素运行一个工作组。
const encoder = device.createCommandEncoder({ label: 'histogram encoder' });
const pass = encoder.beginComputePass();
pass.setPipeline(pipeline);
pass.setBindGroup(0, bindGroup);
- pass.dispatchWorkgroups(1);
+ pass.dispatchWorkgroups(texture.width, texture.height);
pass.end();
运行效果如下
出了什么问题?为什么这个直方图与之前的直方图不匹配?为什么总数也不匹配? 注意:你的电脑可能得到与我不同的结果。在我这里,上图是之前版本的结果,下面是 4 个新版本的结果。

新版本得到了不一致的结果(至少在我的机器上)。
发生了什么?
这就是上一篇文章中提到的经典竞态条件。
着色器中的这行代码
bins[bin] += 1;
实际上会被翻译成
let value = bins[bin]; value = value + 1 bins[bin] = value;
当两个或多个调用并行运行时,恰好命中同一个 bin 值时会发生什么?
假设有 2 个调用,bin = 1,bins[1] = 3。如果它们并行运行,两个调用都会加载 3,
都会写入 4,而正确答案应该是 5。
| 调用 1 | 调用 2 |
|---|---|
| value = bins[bin] // 加载 3 | value = bins[bin] // 加载 3 |
| value = value + 1 // 加 1 | value = value + 1 // 加 1 |
| bins[bin] = value // 存储 4 | bins[bin] = value // 存储 4 |
你可以从下面的图表中直观地看到问题。你会看到多个调用去获取箱子中的当前值,加 1,再放回去, 而它们各自都"无视"了另一个调用同时在读取和更新同一个箱子。
WGSL 有特殊的"原子"指令来解决这个问题。在这种情况下,我们可以使用 atomicAdd。
atomicAdd 使加法"原子化",这意味着不是 3 个操作(加载->加->存储),
所有 3 个操作同时"原子地"发生。这有效地防止了多个调用同时更新同一个值。
原子函数有一个要求:它们只能作用于 i32 或 u32 类型,并且数据本身必须是 atomic 类型。
下面是对着色器的改动
-@group(0) @binding(0) var<storage, read_write> bins: array<u32>;
+@group(0) @binding(0) var<storage, read_write> bins: array<atomic<u32>>;
@group(0) @binding(1) var ourTexture: texture_2d<f32>;
const kSRGBLuminanceFactors = vec3f(0.2126, 0.7152, 0.0722);
fn srgbLuminance(color: vec3f) -> f32 {
return saturate(dot(color, kSRGBLuminanceFactors));
}
@compute @workgroup_size(1, 1, 1)
fn cs(@builtin(global_invocation_id) global_invocation_id: vec3u) {
let numBins = f32(arrayLength(&bins));
let lastBinIndex = u32(numBins - 1);
let position = global_invocation_id.xy;
let color = textureLoad(ourTexture, position, 0);
let v = srgbLuminance(color.rgb);
let bin = min(u32(v * numBins), lastBinIndex);
- bins[bin] += 1;
+ atomicAdd(&bins[bin], 1u);
}
这样,使用每个像素一个工作组调用的计算着色器就可以正常工作了!
不幸的是,我们遇到了一个新问题。atomicAdd 实际上需要阻止其他调用同时更新同一个箱子。我们可以看到这个问题。下面的图表将 atomicAdd 展示为 3 个操作,
但当一个调用正在执行 atomicAdd 时,它会"锁定"该箱子,
使得另一个调用必须等待它完成。
在图表中,当一个调用锁定一个箱子时,会有一条从该调用到该箱子的线,颜色为该箱子的颜色。 正在等待该箱子解锁的调用会在其上显示一个停车标志 🛑。
在我的机器上,新版本比 JavaScript 快约 4 倍,不过实际结果因机器而异。
工作组
我们能更快吗?正如上一篇文章提到的,
"工作组"是我们能要求 GPU 执行的最小工作单元。你在创建着色器模块时以三维方式定义工作组的大小,
然后调用 dispatchWorkgroups 来运行多个工作组。
工作组可以共享内部存储,并在工作组内部协调这些存储。我们怎样才能利用这一点?
让我们尝试这样:将工作组大小设为 256x1(即每个工作组 256 个调用)。
让每个调用处理图像的一个 256x1 区域。这意味着我们将会有 Math.ceil(texture.width / 256) * texture.height 个工作组。
对于我们的图像(2448 × 1505),即 10 × 1505 = 15050 个工作组。
我们会让工作组内的调用使用工作组存储来将亮度值累计到箱子中。
最后,我们将把工作组内存复制到它自己的"块"(chunk)中。 这样我们就不需要与其他工作组协调了。 完成后,我们会再运行一个计算着色器来汇总这些块。
让我们编辑着色器。首先将 bins 从 storage 类型改为 workgroup 类型,
这样它们只会在同一工作组内的调用之间共享。
-@group(0) @binding(0) var<storage, read_write> bins: array<atomic<u32>>; +const chunkWidth = 256; +const chunkHeight = 1; +const chunkSize = chunkWidth * chunkHeight; +var<workgroup> bins: array<atomic<u32>, chunkSize>;
上面我们声明了一些常量,这样方便以后更改。
然后我们需要为所有块创建存储
+@group(0) @binding(0) var<storage, read_write> chunks: array<array<u32, chunkSize>>;
@group(0) @binding(1) var ourTexture: texture_2d<f32>;
const kSRGBLuminanceFactors = vec3f(0.2126, 0.7152, 0.0722);
fn srgbLuminance(color: vec3f) -> f32 {
return saturate(dot(color, kSRGBLuminanceFactors));
}
我们可以用这些常量来定义工作组大小
-@compute @workgroup_size(1, 1, 1) +@compute @workgroup_size(chunkWidth, chunkHeight, 1)
主要的箱子递增部分与之前的着色器非常相似。
fn cs(@builtin(global_invocation_id) global_invocation_id: vec3u) {
let size = textureDimensions(ourTexture, 0);
let position = global_invocation_id.xy;
+ if (all(position < size)) {
- let numBins = f32(arrayLength(&bins));
+ let numBins = f32(chunkSize);
let lastBinIndex = u32(numBins - 1);
let color = textureLoad(ourTexture, position, 0);
let v = srgbLuminance(color.rgb);
let bin = min(u32(v * numBins), lastBinIndex);
atomicAdd(&bins[bin], 1u);
}
因为块大小是硬编码在着色器中的,我们不想处理纹理外的像素。比如如果图像宽度是 300 像素,
第一个工作组会处理像素 0 到 255,第二个工作组会处理像素 256 到 511。
但我们只需要处理到像素 299。if(all(position < size)) 就是做这件事的。
position 和 size 都是 vec2u,所以 position < size 会产生两个布尔值,即 vec2<bool>。
all 函数在所有输入都为真时返回真。所以,只有当 position.x < size.x 且 position.y < size.y 时,
代码才会进入 if 内部。
至于 numBins,我们有多少个箱子,取决于我们为块大小定义的数值。
我们无法再查询大小,因为 var<workgroup> 类型不像 var<storage> 那样传入缓冲区。
它的大小是在创建着色器模块时定义的。
最后,着色器中变化最大的部分。
workgroupBarrier(); let chunksAcross = (size.x + chunkWidth - 1) / chunkWidth; let chunkDim = vec2u(chunkWidth, chunkHeight); let chunkPos = global_invocation_id.xy / chunkDim; let chunk = chunkPos.y * chunksAcross + chunkPos.x; let binPos = global_invocation_id.xy % chunkDim; let bin = binPos.y * chunkWidth + binPos.x; chunks[chunk][bin] = atomicLoad(&bins[bin]); }
这部分让每个调用将一个箱子复制到对应块中该工作组正在处理的块。
其中一些计算是将 global_invocation_id 转换为 chunkPos 和 binPos。
这些值实际上就是 workgroup_id 和 local_invocation_id,所以我们可以将代码简化为
workgroupBarrier(); let chunksAcross = (size.x + chunkWidth - 1) / chunkWidth; let chunk = workgroup_id.y * chunksAcross + workgroup_id.x; let bin = local_invocation_id.y * chunkWidth + local_invocation_id.x; chunks[chunk][bin] = atomicLoad(&bins[bin]); }
然后我们需要在着色器函数中添加 workgroup_id 和 local_invocation_id 作为输入
-fn cs(@builtin(global_invocation_id) global_invocation_id: vec3u) {
+fn cs(
+ @builtin(global_invocation_id) global_invocation_id: vec3u,
+ @builtin(workgroup_id) workgroup_id: vec3u,
+ @builtin(local_invocation_id) local_invocation_id: vec3u,
+) {
...
workgroupBarrier
workgroupBarrier() 相当于说"在这里停住,直到工作组中所有调用都到达这一点"。
我们需要这个是因为每个调用在更新 bins 中不同的元素,但之后每个调用会从 bins 中
各自复制一个元素到其中一个 chunks 的对应元素,所以我们需要确保所有其他调用都完成了。
换一种说法,任何调用都可能根据它从纹理读取的颜色对 bins 中的任何元素执行 atomicAdd。
但是,只有 local_invocation_id = (3, 0) 会将 bins[3] 复制到 chunks[chunk][3],
所以它必须等待所有其他调用都有机会更新 bins[3]。
综合起来,这是我们新的着色器
const chunkWidth = 256;
const chunkHeight = 1;
const chunkSize = chunkWidth * chunkHeight;
var<workgroup> bins: array<atomic<u32>, chunkSize>;
@group(0) @binding(0) var<storage, read_write> chunks: array<array<u32, chunkSize>>;
@group(0) @binding(1) var ourTexture: texture_2d<f32>;
const kSRGBLuminanceFactors = vec3f(0.2126, 0.7152, 0.0722);
fn srgbLuminance(color: vec3f) -> f32 {
return saturate(dot(color, kSRGBLuminanceFactors));
}
@compute @workgroup_size(chunkWidth, chunkHeight, 1)
fn cs(
@builtin(global_invocation_id) global_invocation_id: vec3u,
@builtin(workgroup_id) workgroup_id: vec3u,
@builtin(local_invocation_id) local_invocation_id: vec3u,
) {
let size = textureDimensions(ourTexture, 0);
let position = global_invocation_id.xy;
if (all(position < size)) {
let numBins = f32(chunkSize);
let lastBinIndex = u32(numBins - 1);
let color = textureLoad(ourTexture, position, 0);
let v = srgbLuminance(color.rgb);
let bin = min(u32(v * numBins), lastBinIndex);
atomicAdd(&bins[bin], 1u);
}
workgroupBarrier();
let chunksAcross = (size.x + chunkWidth - 1) / chunkWidth;
let chunk = workgroup_id.y * chunksAcross + workgroup_id.x;
let bin = local_invocation_id.y * chunkWidth + local_invocation_id.x;
chunks[chunk][bin] = atomicLoad(&bins[bin]);
}
我们还可以做一件事:不将 chunkWidth 和 chunkHeight 硬编码,
而是从 JavaScript 传入,可以这样做
+ const k = {
+ chunkWidth: 256,
+ chunkHeight: 1,
+ };
+ const sharedConstants = Object.entries(k)
+ .map(([k, v]) => `const ${k} = ${v};`)
+ .join('\n');
const histogramChunkModule = device.createShaderModule({
label: 'histogram chunk shader',
code: /* wgsl */ `
- const chunkWidth = 256;
- const chunkHeight = 1;
+ ${sharedConstants}
const chunkSize = chunkWidth * chunkHeight;
var<workgroup> bins: array<atomic<u32>, chunkSize>;
@group(0) @binding(0) var<storage, read_write> chunks: array<array<u32, chunkSize>>;
@group(0) @binding(1) var ourTexture: texture_2d<f32>;
...
`,
});
如果运行这个着色器,它的工作方式大致如下:
如上所示,每个工作组读取一块像素,并相应地更新箱子。
和之前一样,如果有 2 个调用需要更新同一个箱子,其中一个必须等待 🛑。
之后它们都在 workgroupBarrier 处等待彼此 🚧。
之后每个调用将自己负责的箱子复制到其正在处理的块的对应箱子中。
汇总块
所有像素的亮度值现在已经被统计了,但我们需要将箱子中的值相加才能得到最终结果。 让我们写一个计算着色器来做这件事。我们可以每个箱子使用一个调用。 每个调用只需要将所有块中相同箱子的值相加,然后将结果写入第一个块
代码如下
const chunkWidth = 256;
const chunkHeight = 1;
const chunkSize = chunkWidth * chunkHeight;
@group(0) @binding(0) var<storage, read_write> chunks: array<array<u32, chunkSize>>;
@compute @workgroup_size(chunkSize, 1, 1)
fn cs(@builtin(local_invocation_id) local_invocation_id: vec3u) {
var sum = u32(0);
let numChunks = arrayLength(&chunks);
for (var i = 0u; i < numChunks; i++) {
sum += chunks[i][local_invocation_id.x];
}
chunks[0][local_invocation_id.x] = sum;
}
和之前一样,我们可以注入 chunkWidth 和 chunkHeight。
const chunkSumModule = device.createShaderModule({
label: 'chunk sum shader',
code: /* wgsl */ `
* ${sharedConstants}
const chunkSize = chunkWidth * chunkHeight;
@group(0) @binding(0) var<storage, read_write> chunks: array<array<u32, chunkSize>>;
@compute @workgroup_size(chunkSize, 1, 1)
...
}
`,
});
这个着色器的工作方式大致如下
现在我们有了这两个着色器,让我们更新代码来使用它们。 我们需要为两个着色器都创建管线
- const pipeline = device.createComputePipeline({
- label: 'histogram',
- layout: 'auto',
- compute: {
- module,
-- },
- });
+ const histogramChunkPipeline = device.createComputePipeline({
+ label: 'histogram',
+ layout: 'auto',
+ compute: {
+ module: histogramChunkModule,
++ },
+ });
+
+ const chunkSumPipeline = device.createComputePipeline({
+ label: 'chunk sum',
+ layout: 'auto',
+ compute: {
+ module: chunkSumModule,
++ },
+ });
我们需要创建一个足够大的存储缓冲区来存放所有块,这样我们 可以计算出需要多少块来覆盖整个图像。
const imgBitmap = await loadImageBitmap('resources/images/pexels-francesco-ungaro-96938-mid.jpg');
const texture = createTextureFromSource(device, imgBitmap);
- const numBins = 256;
- const histogramBuffer = device.createBuffer({
- size: numBins * 4, // 256 entries * 4 bytes per (u32)
- usage: GPUBufferUsage.STORAGE | GPUBufferUsage.COPY_SRC,
- });
+ const chunkSize = k.chunkWidth * k.chunkHeight;
+ const chunksAcross = Math.ceil(texture.width / k.chunkWidth);
+ const chunksDown = Math.ceil(texture.height / k.chunkHeight);
+ const numChunks = chunksAcross * chunksDown;
+ const chunksBuffer = device.createBuffer({
+ size: numChunks * chunkSize * 4, // 4 bytes per (u32)
+ usage: GPUBufferUsage.STORAGE | GPUBufferUsage.COPY_SRC,
+ });
我们仍然需要一个结果缓冲区来读取结果,但它的大小不再是之前的大小了
const resultBuffer = device.createBuffer({
- size: histogramBuffer.size,
+ size: chunkSize * 4, // 4 bytes per (u32)
usage: GPUBufferUsage.COPY_DST | GPUBufferUsage.MAP_READ,
});
我们需要为每个 pass 创建一个绑定组。一个用于将纹理和块传递给第一个着色器, 另一个用于将块传递给第二个着色器
- const bindGroup = device.createBindGroup({
+ const histogramBindGroup = device.createBindGroup({
label: 'histogram bindGroup',
layout: histogramChunkPipeline.getBindGroupLayout(0),
entries: [
- { binding: 0, resource: histogramBuffer },
+ { binding: 0, resource: chunksBuffer },
{ binding: 1, resource: texture },
],
});
const chunkSumBindGroup = device.createBindGroup({
label: 'sum bindGroup',
layout: chunkSumPipeline.getBindGroupLayout(0),
entries: [
{ binding: 0, resource: chunksBuffer },
],
});
最后我们可以运行着色器了。首先是读取像素并按箱子分类的部分, 我们为每个块分发一个工作组。
const encoder = device.createCommandEncoder({ label: 'histogram encoder' });
const pass = encoder.beginComputePass();
+ // 为每个区域创建直方图
- pass.setPipeline(pipeline);
- pass.setBindGroup(0, bindGroup);
- pass.dispatchWorkgroups(texture.width, texture.height);
+ pass.setPipeline(histogramChunkPipeline);
+ pass.setBindGroup(0, histogramBindGroup);
+ pass.dispatchWorkgroups(chunksAcross, chunksDown);
然后我们需要运行汇总块的着色器。它只需要 1 个工作组, 每个箱子使用 1 个调用(256 个调用)。
+ // 汇总各个区域 + pass.setPipeline(chunkSumPipeline); + pass.setBindGroup(0, chunkSumBindGroup); + pass.dispatchWorkgroups(1);
其余代码相同。
在我的机器上计时,第一个着色器在 0.2ms 内运行完毕!我很高兴地看到它读取了整个图像并迅速填满了所有块!
不幸的是,汇总块的部分花了更长的时间。11ms 这比之前的着色器更慢!
在另一台机器上,之前的方案是 4.4ms,新的方案是 1.7ms,所以并非完全失败。
我们能做得更好吗?
归约(Reduce)
上面的方案只使用了一个工作组。尽管它有 256 个调用, 现代 GPU 有数千个核心,而我们只用到了其中 256 个。
我们可以尝试一种叫做归约的技术。我们会让每个工作组只相加 2 个块, 将结果写入这两个块中的第一个。这样,如果我们有 1000 个块, 我们可以用 500 个工作组。这就有了更多的并行化。 我们重复这个过程:500 个块归约为 250,250 -> 125,125 -> 63… 直到归约为 1 个块。
我们可以只使用一个着色器,只需要传入一个步幅(stride)来逐步将块归约到只剩一个块。 步幅是到达我们正在相加的第二个块需要前进的块数。 如果传入步幅为 1,则相加相邻的块。如果传入步幅为 2,则每隔一块相加。依此类推…
这是对着色器的改动
const chunkSumModule = device.createShaderModule({
label: 'chunk sum shader',
code: /* wgsl */ `
${sharedConstants}
const chunkSize = chunkWidth * chunkHeight;
+ struct Uniforms {
+ stride: u32,
+ };
@group(0) @binding(0) var<storage, read_write> chunks: array<array<vec4u, chunkSize>>;
+ @group(0) @binding(1) var<uniform> uni: Uniforms;
@compute @workgroup_size(chunkSize, 1, 1) fn cs(
@builtin(local_invocation_id) local_invocation_id: vec3u,
@builtin(workgroup_id) workgroup_id: vec3u,
) {
- var sum = u32(0);
- let numChunks = arrayLength(&chunks);
- for (var i = 0u; i < numChunks; i++) {
- sum += chunks[i][local_invocation_id.x];
- }
- chunks[0][local_invocation_id.x] = sum;
+ let chunk0 = workgroup_id.x * uni.stride * 2;
+ let chunk1 = chunk0 + uni.stride;
+
+ let sum = chunks[chunk0][local_invocation_id.x] +
+ chunks[chunk1][local_invocation_id.x];
+ chunks[chunk0][local_invocation_id.x] = sum;
}
`,
});
如上所示,我们根据 workgroup_id.x 和作为 uniform 传入的 uni.stride 计算 chunk0 和 chunk1。
然后将两个块中对应箱子的 2 个值相加,存储回第一个块中。
如果我们用正确的调用数量和步幅设置来运行它,它的工作方式大致如下。 注意:变暗的块是不再使用的块。
为了让这个新方案工作,我们需要为每个步幅值添加一个 uniform 缓冲区, 以及一个绑定组。
const sumBindGroups = [];
const numSteps = Math.ceil(Math.log2(numChunks));
for (let i = 0; i < numSteps; ++i) {
const stride = 2 ** i;
const uniformBuffer = device.createBuffer({
size: 4,
usage: GPUBufferUsage.UNIFORM,
mappedAtCreation: true,
});
new Uint32Array(uniformBuffer.getMappedRange()).set([stride]);
uniformBuffer.unmap();
const chunkSumBindGroup = device.createBindGroup({
layout: chunkSumPipeline.getBindGroupLayout(0),
entries: [
{ binding: 0, resource: chunksBuffer },
{ binding: 1, resource: uniformBuffer },
],
});
sumBindGroups.push(chunkSumBindGroup);
}
然后我们只需要用正确数量的 dispatch 调用它们, 直到将块归约到只剩 1 个
- // sum the areas
- pass.setPipeline(chunkSumPipeline);
- pass.setBindGroup(0, chunkSumBindGroup);
- pass.dispatchWorkgroups(1);
+ // reduce the chunks
+ const pass = encoder.beginComputePass();
+ pass.setPipeline(chunkSumPipeline);
+ let chunksLeft = numChunks;
+ sumBindGroups.forEach(bindGroup => {
+ pass.setBindGroup(0, bindGroup);
+ const dispatchCount = Math.floor(chunksLeft / 2);
+ chunksLeft -= dispatchCount;
+ pass.dispatchWorkgroups(dispatchCount);
+ });
计时这个版本,我在两台测试的机器上都得到了不到 1ms 的结果!🎉🚀
以下是各台机器的计时结果
可能还有更快的计算直方图的方法。也可能尝试不同的块大小会更好。 比如 16x16 可能比 256x1 更好。 此外,WebGPU 将来可能会支持 子组(subgroups),这又是另一个全新的主题, 也是进一步优化的领域。
目前我希望这些示例能给你一些关于如何编写和优化计算着色器的思路。 要点总结:
-
想办法利用 GPU 提供的所有并行化能力
-
注意竞态条件
-
使用
var<workgroup>在工作组的所有调用之间创建共享存储 -
尽量设计需要较少调用间协调的算法
-
当需要协调时,原子操作是一个解决方案,
workgroupBarrier也是在这方面我们做得一般。在工作组内存中计算块时,我们仍然有冲突, 通过
atomicAdd解决了,但从工作组中的bins复制到chunks时没有冲突, 归约chunks到最终结果时也没有冲突
还有一条
-
不要认为 GPU 一定很快
我们了解到 GPU 的单个核心并不快。所有速度都来自于并行化, 所以我们需要设计并行的解决方案。
在下一篇文章中,我们将对这些进行一些调整, 并改为使用 GPU 来绘制结果而不是将数据拉回到 JavaScript。 我们还将尝试基于创建的图像直方图进行一些实时视频调整。