Compute Shaders en WebGPU - Histograma de Imagen Parte 2
En el artículo anterior cubrimos cómo crear un histograma de imagen en JavaScript y luego lo convertimos para usar WebGPU, pasando por varios pasos de optimización.
Hagamos algunas cosas más con él.
Generar 4 histogramas a la vez
Dada una imagen como esta:

Es común generar múltiples histogramas:
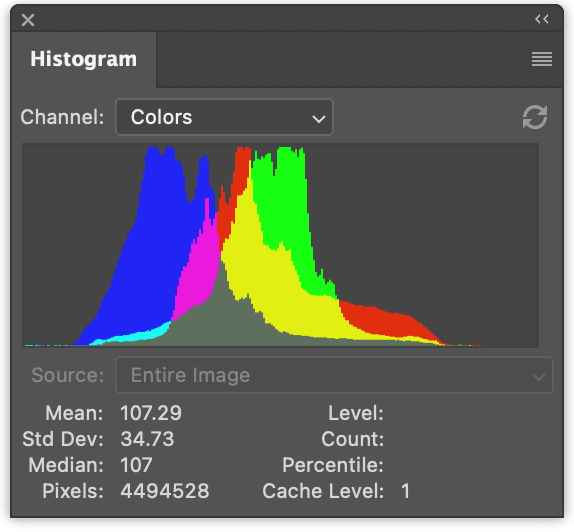
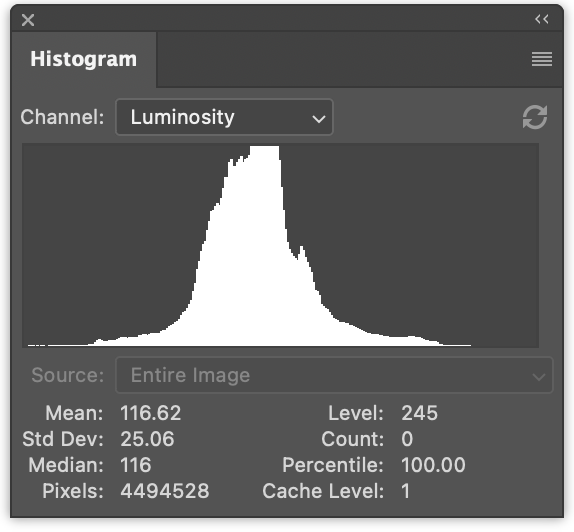
A la izquierda tenemos 3 histogramas (uno para los valores rojos, uno para los verdes y uno para los azules) dibujados de forma solapada. A la derecha tenemos un histograma de luminancia como el que generamos en el artículo anterior.
Es un cambio minúsculo generar los 4 a la vez.
En JavaScript, aquí están los cambios para generar 4 histogramas simultáneamente:
function computeHistogram(numBins, imgData) {
const {width, height, data} = imgData;
- const bins = new Array(numBins).fill(0);
+ const bins = new Array(numBins * 4).fill(0);
for (let y = 0; y < height; ++y) {
for (let x = 0; x < width; ++x) {
const offset = (y * width + x) * 4;
- const r = data[offset + 0] / 255;
- const g = data[offset + 1] / 255;
- const b = data[offset + 2] / 255;
- const v = srgbLuminance(r, g, b);
-
- const bin = Math.min(numBins - 1, v * numBins) | 0;
- ++bins[bin];
+ for (let ch = 0; ch < 4; ++ch) {
+ const v = ch < 3
+ ? data[offset + ch] / 255
+ : srgbLuminance(data[offset + 0] / 255,
+ data[offset + 1] / 255,
+ data[offset + 2] / 255);
+ const bin = Math.min(numBins - 1, v * numBins) | 0;
+ ++bins[bin * 4 + ch];
+ }
}
}
return bins;
}
Esto generará los histogramas entrelazados: r, g, b, l, r, g, b, l…
Podemos actualizar el código para renderizarlos así:
function drawHistogram(histogram, numEntries, channels, height = 100) {
- const numBins = histogram.length;
- const max = Math.max(...histogram);
- const scale = Math.max(1 / max);//, 0.2 * numBins / numEntries);
+ // encontrar el valor más alto para cada canal
+ const numBins = histogram.length / 4;
+ const max = [0, 0, 0, 0];
+ histogram.forEach((v, ndx) => {
+ const ch = ndx % 4;
+ max[ch] = Math.max(max[ch], v);
+ });
+ const scale = max.map(max => Math.max(1 / max, 0.2 * numBins / numEntries));
const canvas = document.createElement('canvas');
canvas.width = numBins;
canvas.height = height;
document.body.appendChild(canvas);
const ctx = canvas.getContext('2d');
+ const colors = [
+ 'rgb(255, 0, 0)',
+ 'rgb(0, 255, 0)',
+ 'rgb(0, 0, 255)',
+ 'rgb(255, 255, 255)',
+ ];
- ctx.fillStyle = '#fff';
+ ctx.globalCompositeOperation = 'screen';
for (let x = 0; x < numBins; ++x) {
- const v = histogram[x] * scale * height;
- ctx.fillRect(x, height - v, 1, v);
+ const offset = x * 4;
+ for (const ch of channels) {
+ const v = histogram[offset + ch] * scale[ch] * height;
+ ctx.fillStyle = colors[ch];
+ ctx.fillRect(x, height - v, 1, v);
+ }
}
}
Y luego llamar a esa función dos veces, una para renderizar los histogramas de color y otra para el de luminancia:
const histogram = computeHistogram(numBins, imgData); showImageBitmap(imgBitmap); + // dibujar los canales rojo, verde y azul const numEntries = imgData.width * imgData.height; - drawHistogram(histogram, numEntries); + drawHistogram(histogram, numEntries, [0, 1, 2]); + + // dibujar el canal de luminosidad + drawHistogram(histogram, numEntries, [3]);
Y ahora obtenemos estos resultados:
Hacer lo mismo en nuestros ejemplos de WGSL es aún más sencillo.
Por ejemplo, nuestro primer ejemplo que era demasiado lento cambiaría así:
-@group(0) @binding(0) var<storage, read_write> bins: array<u32>;
+@group(0) @binding(0) var<storage, read_write> bins: array<vec4u>;
@group(0) @binding(1) var ourTexture: texture_2d<f32>;
// de: https://www.w3.org/WAI/GL/wiki/Relative_luminance
const kSRGBLuminanceFactors = vec3f(0.2126, 0.7152, 0.0722);
fn srgbLuminance(color: vec3f) -> f32 {
return saturate(dot(color, kSRGBLuminanceFactors));
}
@compute @workgroup_size(1, 1, 1) fn cs() {
let size = textureDimensions(ourTexture, 0);
let numBins = f32(arrayLength(&bins));
let lastBinIndex = u32(numBins - 1);
for (var y = 0u; y < size.y; y++) {
for (var x = 0u; x < size.x; x++) {
let position = vec2u(x, y);
- let color = textureLoad(ourTexture, position, 0);
- let v = srgbLuminance(color.rgb);
- let bin = min(u32(v * numBins), lastBinIndex);
- bins[bin] += 1;
+ var channels = textureLoad(ourTexture, position, 0);
+ channels.w = srgbLuminance(channels.rgb);
+ for (var ch = 0; ch < 4; ch++) {
+ let v = channels[ch];
+ let bin = min(u32(v * numBins), lastBinIndex);
+ bins[bin][ch] += 1;
+ }
}
}
}
Necesitábamos hacer espacio para los 4 canales cambiando bins de array<u32> a array<vec4u>. Luego extrajimos el color de la textura, calculamos la luminancia y la pusimos en el elemento w de channels.
var channels = textureLoad(ourTexture, position, 0); channels.w = srgbLuminance(channels.rgb);
De esta manera podríamos simplemente recorrer los 4 canales e incrementar el bin correcto.
El único otro cambio que necesitamos es asignar 4 veces más memoria para nuestro buffer:
const histogramBuffer = device.createBuffer({
- size: numBins * 4, // 256 entradas * 4 bytes por (u32)
+ size: 256 * 4 * 4, // 256 entradas * 4 (rgba) * 4 bytes por (u32)
usage: GPUBufferUsage.STORAGE | GPUBufferUsage.COPY_SRC,
});
Y aquí está nuestra versión lenta de WebGPU generando 4 histogramas:
Haciendo cambios similares a nuestra versión más rápida:
const chunkWidth = 256;
const chunkHeight = 1;
const chunkSize = chunkWidth * chunkHeight;
-var<workgroup> bins: array<atomic<u32>, chunkSize>;
-@group(0) @binding(0) var<storage, read_write> chunks: array<array<u32, chunkSize>>;
+var<workgroup> bins: array<array<atomic<u32>, 4>, chunkSize>;
+@group(0) @binding(0) var<storage, read_write> chunks: array<array<vec4u, chunkSize>>;
@group(0) @binding(1) var ourTexture: texture_2d<f32>;
const kSRGBLuminanceFactors = vec3f(0.2126, 0.7152, 0.0722);
fn srgbLuminance(color: vec3f) -> f32 {
return saturate(dot(color, kSRGBLuminanceFactors));
}
@compute @workgroup_size(chunkWidth, chunkHeight, 1)
fn cs(
@builtin(workgroup_id) workgroup_id: vec3u,
@builtin(local_invocation_id) local_invocation_id: vec3u,
) {
let size = textureDimensions(ourTexture, 0);
let position = workgroup_id.xy * vec2u(chunkWidth, chunkHeight) +
local_invocation_id.xy;
if (all(position < size)) {
let numBins = f32(chunkSize);
let lastBinIndex = u32(numBins - 1);
- let color = textureLoad(ourTexture, position, 0);
- let v = srgbLuminance(color.rgb);
- let bin = min(u32(v * numBins), lastBinIndex);
- atomicAdd(&bins[bin], 1u);
+ var channels = textureLoad(ourTexture, position, 0);
+ channels.w = srgbLuminance(channels.rgb);
+ for (var ch = 0; ch < 4; ch++) {
+ let v = channels[ch];
+ let bin = min(u32(v * numBins), lastBinIndex);
+ atomicAdd(&bins[bin][ch], 1u);
+ }
}
workgroupBarrier();
let chunksAcross = (size.x + chunkWidth - 1) / chunkWidth;
let chunk = workgroup_id.y * chunksAcross + workgroup_id.x;
let bin = local_invocation_id.y * chunkWidth + local_invocation_id.x;
- chunks[chunk][bin] = atomicLoad(&bins[bin]);
+ chunks[chunk][bin] = vec4u(
+ atomicLoad(&bins[bin][0]),
+ atomicLoad(&bins[bin][1]),
+ atomicLoad(&bins[bin][2]),
+ atomicLoad(&bins[bin][3]),
+ );
}
Y para nuestro shader de reducción:
const chunkWidth = 256;
const chunkHeight = 1;
const chunkSize = chunkWidth * chunkHeight;
struct Uniforms {
stride: u32,
};
-@group(0) @binding(0) var<storage, read_write> chunks: array<array<u32, chunkSize>>;
+@group(0) @binding(0) var<storage, read_write> chunks: array<array<vec4u, chunkSize>>;
@group(0) @binding(1) var<uniform> uni: Uniforms;
@compute @workgroup_size(chunkSize, 1, 1) fn cs(
@builtin(local_invocation_id) local_invocation_id: vec3u,
@builtin(workgroup_id) workgroup_id: vec3u,
) {
let chunk0 = workgroup_id.x * uni.stride * 2;
let chunk1 = chunk0 + uni.stride;
let sum = chunks[chunk0][local_invocation_id.x] +
chunks[chunk1][local_invocation_id.x];
chunks[chunk0][local_invocation_id.x] = sum;
}
Al igual que en el ejemplo anterior, necesitamos aumentar los tamaños de los buffers:
const chunksBuffer = device.createBuffer({
- size: numChunks * chunkSize * 4, // 4 bytes por (u32)
+ size: numChunks * chunkSize * 4 * 4, // 16 bytes por (vec4u)
usage: GPUBufferUsage.STORAGE | GPUBufferUsage.COPY_SRC,
});
const resultBuffer = device.createBuffer({
- size: chunkSize * 4,
+ size: chunkSize * 4 * 4,
usage: GPUBufferUsage.COPY_DST | GPUBufferUsage.MAP_READ,
});
Eso es todo.
Hubo otros 2 pasos que probamos en el artículo anterior. Uno usaba un solo workgroup por píxel. Otro sumaba los chunks con una invocación por bin en lugar de reducir los bins.
Aquí hay algo de información sobre los tiempos que obtiuve probando estas versiones de 4 canales.
Puedes compararlos con las versiones de 1 canal del artículo anterior.
Dibujando el histograma en la GPU
Vamos a dibujar el histograma en la GPU. En JavaScript usamos la API de canvas 2D para dibujar un rectángulo de 1 por la altura para cada bin, lo cual fue muy fácil. Podríamos hacer eso usando WebGPU también, pero creo que hay un mejor enfoque para el caso particular de dibujar un histograma.
En su lugar, simplemente dibujaremos un rectángulo. Dibujar rectángulos lo hemos cubierto en muchos lugares. Por ejemplo, la mayoría de los ejemplos de los artículos sobre texturas usan un rectángulo.
Para un histograma, en el fragment shader (shader de fragmentos), podríamos pasar una coordenada de textura y convertir la parte horizontal de 0 -> 1 a 0 -> numBins - 1. Podríamos entonces buscar el valor en ese bin y calcular una altura en el rango de 0 a 1. Podríamos entonces comparar eso con nuestra coordenada de textura vertical. Si la coordenada de textura está por encima de la altura, podríamos dibujar 0; si está por debajo, podríamos dibujar algún color.
Esto funcionaría para 1 canal, pero nos gustaría dibujar múltiples canales. Así que, en su lugar, estableceremos un bit para cada canal que esté por encima de la altura y luego usaremos esos 4 bits para buscar uno de los 16 colores. Esto también nos permitirá seleccionar los colores que queremos para representar cada canal y sus combinaciones.
Aquí hay un fragment shader que hace esto:
struct Uniforms {
matrix: mat4x4f, // <- usado por el vertex shader
colors: array<vec4f, 16>,
channelMult: vec4u,
};
@group(0) @binding(0) var<storage, read> bins: array<vec4u>;
@group(0) @binding(1) var<uniform> uni: Uniforms;
@group(0) @binding(2) var<storage, read_write> scale: vec4f;
@fragment fn fs(fsInput: OurVertexShaderOutput) -> @location(0) vec4f {
let numBins = arrayLength(&bins);
let lastBinIndex = u32(numBins - 1);
let bin = clamp(
u32(fsInput.texcoord.x * f32(numBins)),
0,
lastBinIndex);
let heights = vec4f(bins[bin]) * scale;
let bits = heights > vec4f(fsInput.texcoord.y);
let ndx = dot(select(vec4u(0), uni.channelMult, bits), vec4u(1));
return uni.colors[ndx];
}
La primera parte es calcular qué bin corresponde basándose en la coordenada de textura horizontal:
let numBins = arrayLength(&bins);
let lastBinIndex = u32(numBins - 1);
let bin = clamp(
u32(fsInput.texcoord.x * f32(numBins)),
0,
lastBinIndex);
La siguiente parte es obtener las alturas de los 4 canales. Estamos multiplicando por scale tal como hicimos en JavaScript. Tendremos que suministrar eso más adelante.
let heights = vec4f(bins[bin]) * scale;
A continuación establecemos 4 booleanos en un vec4<bool>, uno para cada canal. Serán verdaderos si la altura del bin es mayor que la coordenada de textura.
let bits = heights > vec4f(fsInput.texcoord.y);
La siguiente parte seleccionará valores de uni.channelMult basándose en esos 4 booleanos y luego sumará los 4 valores. Poder pasar uni.channelMult es similar a lo que hicimos en JavaScript, permitiéndonos elegir qué canales se dibujan. Por ejemplo, si establecemos channelMult a 1, 2, 4, 0, obtendremos los histogramas rojo, verde y azul.
let ndx = dot(select(vec4u(0), uni.channelMult, bits), vec4u(1));
Esta última parte busca uno de nuestros 16 colores.
return uni.colors[ndx];
También necesitamos un shader para calcular scale. En JavaScript hicimos esto:
const numBins = histogram.length / 4;
const max = [0, 0, 0, 0];
histogram.forEach((v, ndx) => {
const ch = ndx % 4;
max[ch] = Math.max(max[ch], v);
});
const scale = max.map(max => Math.max(1 / max, 0.2 * numBins / numEntries));
Para hacer lo mismo en un compute shader podríamos hacer algo como esto:
@group(0) @binding(0) var<storage, read> bins: array<vec4u>;
@group(0) @binding(1) var<storage, read_write> scale: vec4f;
@group(0) @binding(2) var ourTexture: texture_2d<f32>;
@compute @workgroup_size(1, 1, 1) fn cs() {
let size = textureDimensions(ourTexture, 0);
let numEntries = f32(size.x * size.y);
var m = vec4u(0);
let numBins = arrayLength(&bins);
for (var i = 0u ; i < numBins; i++) {
m = max(m, bins[i]);
}
scale = max(1.0 / vec4f(m), vec4f(0.2 * f32(numBins) / numEntries));
}
Ten en cuenta que la única razón por la que pasamos ourTexture es para obtener su tamaño y así poder calcular numEntries, mientras que en JavaScript pasábamos numEntries. También podríamos usar un uniform para pasar numEntries, pero entonces tendríamos que crear un buffer de uniform, actualizarlo con el valor de numEntries, vincularlo, etc. Pareció más fácil referenciar la textura directamente.
Otra cosa a considerar es que este es otro lugar donde estamos usando un solo núcleo. Podríamos reducir (reduce) aquí también, pero solo hay numBins pasos, que son solo 256. El gasto adicional (overhead) de despachar un montón de pasos de reducción probablemente superaría la paralización. Lo medí y me dio alrededor de 0.1 ms, al menos en una máquina.
Así que lo que queda es unir las piezas.
Dado que vamos a dibujar en el canvas con la GPU, necesitamos obtener el formato preferido del canvas:
const presentationFormat = navigator.gpu.getPreferredCanvasFormat();
Necesitamos crear los módulos de shader con los 2 shaders de arriba y crear pipelines para cada uno.
const scaleModule = device.createShaderModule({
label: 'histogram scale shader',
code: /* wgsl */ `
@group(0) @binding(0) var<storage, read> bins: array<vec4u>;
@group(0) @binding(1) var<storage, read_write> scale: vec4f;
@group(0) @binding(2) var ourTexture: texture_2d<f32>;
@compute @workgroup_size(1, 1, 1) fn cs() {
let size = textureDimensions(ourTexture, 0);
let numEntries = f32(size.x * size.y);
var m = vec4u(0);
let numBins = arrayLength(&bins);
for (var i = 0u ; i < numBins; i++) {
m = max(m, bins[i]);
}
scale = max(1.0 / vec4f(m), vec4f(0.2 * f32(numBins) / numEntries));
}
`,
});
const drawHistogramModule = device.createShaderModule({
label: 'draw histogram shader',
code: /* wgsl */ `
struct OurVertexShaderOutput {
@builtin(position) position: vec4f,
@location(0) texcoord: vec2f,
};
struct Uniforms {
matrix: mat4x4f,
colors: array<vec4f, 16>,
channelMult: vec4u,
};
@group(0) @binding(0) var<storage, read> bins: array<vec4u>;
@group(0) @binding(1) var<uniform> uni: Uniforms;
@group(0) @binding(2) var<storage, read_write> scale: vec4f;
@vertex fn vs(
@builtin(vertex_index) vertexIndex : u32
) -> OurVertexShaderOutput {
let pos = array(
// 1er triángulo
vec2f( 0.0, 0.0), // centro
vec2f( 1.0, 0.0), // derecha, centro
vec2f( 0.0, 1.0), // centro, arriba
// 2do triángulo
vec2f( 0.0, 1.0), // centro, arriba
vec2f( 1.0, 0.0), // derecha, centro
vec2f( 1.0, 1.0), // derecha, arriba
);
var vsOutput: OurVertexShaderOutput;
let xy = pos[vertexIndex];
vsOutput.position = uni.matrix * vec4f(xy, 0.0, 1.0);
vsOutput.texcoord = xy;
return vsOutput;
}
@fragment fn fs(fsInput: OurVertexShaderOutput) -> @location(0) vec4f {
let numBins = arrayLength(&bins);
let lastBinIndex = u32(numBins - 1);
let bin = clamp(
u32(fsInput.texcoord.x * f32(numBins)),
0,
lastBinIndex);
let heights = vec4f(bins[bin]) * scale;
let bits = heights > vec4f(fsInput.texcoord.y);
let ndx = dot(select(vec4u(0), uni.channelMult, bits), vec4u(1));
return uni.colors[ndx];
}
`,
});
const scalePipeline = device.createComputePipeline({
label: 'scale',
layout: 'auto',
compute: {
module: scaleModule,
},
});
const drawHistogramPipeline = device.createRenderPipeline({
label: 'draw histogram',
layout: 'auto',
vertex: {
module: drawHistogramModule,
},
fragment: {
module: drawHistogramModule,
targets: [{ format: presentationFormat }],
},
});
Ya no necesitamos el buffer de resultados puesto que no vamos a leer los valores de vuelta, pero necesitamos un buffer de escala para almacenar la escala que vamos a calcular.
- const resultBuffer = device.createBuffer({
- size: chunkSize * 4 * 4,
- usage: GPUBufferUsage.COPY_DST | GPUBufferUsage.MAP_READ,
- });
+ const scaleBuffer = device.createBuffer({
+ size: 4 * 4,
+ usage: GPUBufferUsage.STORAGE,
+ });
Necesitamos un bind group para nuestra pipeline de escala que tenga los chunks, el buffer de escala y la textura.
const scaleBindGroup = device.createBindGroup({
layout: scalePipeline.getBindGroupLayout(0),
entries: [
{
binding: 0,
resource: {
buffer: chunksBuffer,
size: chunkSize * 4 * 4,
},
},
{ binding: 1, resource: scaleBuffer },
{ binding: 2, resource: texture },
],
});
Arriba establecimos el tamaño del binding para el chunksBuffer para que sea solo el tamaño del primer chunk. De esta manera, en el shader, este código:
@group(0) @binding(0) var<storage, read> bins: array<vec4u>;
...
let numBins = arrayLength(&bins);
obtendrá el valor correcto. Si no especificáramos el tamaño, entonces todo el tamaño de chunksBuffer estaría disponible y numBins se calcularía a partir de todos los chunks, no solo del primero.
Ahora, después de haber reducido los chunks en un solo chunk, podemos ejecutar nuestro compute shader de escala para calcular la escala y, dado que ya no tenemos un buffer de resultados, ya no necesitamos copiar el primer chunk en él, ni necesitamos mapear el buffer de resultados, ni necesitamos pasar numEntries ya que usábamos eso para calcular la escala pero ya lo hemos hecho. Tampoco vamos a pasar histogram, que es el dato que obteníamos del buffer de resultados. Nuestros datos ya están en el chunksBuffer.
+ // Calcular escalas para los canales + pass.setPipeline(scalePipeline); + pass.setBindGroup(0, scaleBindGroup); + pass.dispatchWorkgroups(1); pass.end(); - encoder.copyBufferToBuffer(chunksBuffer, 0, resultBuffer, 0, resultBuffer.size); const commandBuffer = encoder.finish(); device.queue.submit([commandBuffer]); - await resultBuffer.mapAsync(GPUMapMode.READ); - const histogram = new Uint32Array(resultBuffer.getMappedRange()); showImageBitmap(imgBitmap); // dibujar los canales rojo, verde y azul - const numEntries = texture.width * texture.height; - drawHistogram(histogram, numEntries, [0, 1, 2]); + drawHistogram([0, 1, 2]); // dibujar el canal de luminosidad - const numEntries = texture.width * texture.height; - drawHistogram(histogram, numEntries, [3]); + drawHistogram([3]); - resultBuffer.unmap();
Ahora necesitamos actualizar nuestra función drawHistogram para renderizar con la GPU.
Primero necesitamos crear un buffer de uniform para pasar nuestros uniforms. Para referencia, aquí están los uniforms de los shaders con los que dibujaremos el histograma:
struct Uniforms {
matrix: mat4x4f,
colors: array<vec4f, 16>,
channelMult: vec4u,
};
Así que aquí está el código para crear un buffer y rellenar el channelMult y los colores:
function drawHistogram(channels, height = 100) {
const numBins = chunkSize;
// matrix: mat4x4f;
// colors: array<vec4f, 16>;
// channelMult: vec4u;
const uniformValuesAsF32 = new Float32Array(16 + 64 + 4 + 4);
const uniformValuesAsU32 = new Uint32Array(uniformValuesAsF32.buffer);
const uniformBuffer = device.createBuffer({
label: 'draw histogram uniform buffer',
size: uniformValuesAsF32.byteLength,
usage: GPUBufferUsage.UNIFORM | GPUBufferUsage.COPY_DST,
});
const subpart = (view, offset, length) => view.subarray(offset, offset + length);
const matrix = subpart(uniformValuesAsF32, 0, 16);
const colors = subpart(uniformValuesAsF32, 16, 64);
const channelMult = subpart(uniformValuesAsU32, 16 + 64, 4);
const range = (i, fn) => new Array(i).fill(0).map((_, i) => fn(i));
channelMult.set(range(4, i => channels.indexOf(i) >= 0 ? 2 ** i : 0));
colors.set([
[0, 0, 0, 1],
[1, 0, 0, 1],
[0, 1, 0, 1],
[1, 1, 0, 1],
[0, 0, 1, 1],
[1, 0, 1, 1],
[0, 1, 1, 1],
[0.5, 0.5, 0.5, 1],
[1, 1, 1, 1],
[1, 1, 1, 1],
[1, 1, 1, 1],
[1, 1, 1, 1],
[1, 1, 1, 1],
[1, 1, 1, 1],
[1, 1, 1, 1],
[1, 1, 1, 1],
].flat());
También necesitamos calcular una matriz usando las matemáticas de matrices como cubrimos en la serie de artículos sobre matemáticas de matrices.
En particular, nuestro shader tiene un quad unitario hardcoded que va de 0 a 1 en X e Y. Si lo escalamos por 2 tanto en X como en Y y le restamos 1, obtendremos un quad que va de -1 a +1 en ambas direcciones, cubriendo el espacio de recorte (clip space). Esta forma de usar un solo quad unitario es común, ya que entonces podemos usar un poco de matemáticas de matrices para dibujar rectángulos en cualquier posición y orientación sin tener que crear datos de vértices especiales.
mat4.identity(matrix);
mat4.translate(matrix, [-1, -1, 0], matrix);
mat4.scale(matrix, [2, 2, 1], matrix);
device.queue.writeBuffer(uniformBuffer, 0, uniformValuesAsF32);
Necesitamos un bindGroup para todo esto:
const bindGroup = device.createBindGroup({
layout: drawHistogramPipeline.getBindGroupLayout(0),
entries: [
{ binding: 0, resource: { buffer: chunksBuffer, size: chunkSize * 4 * 4 }},
{ binding: 1, resource: uniformBuffer },
{ binding: 2, resource: scaleBuffer },
],
});
Necesitamos un canvas configurado para WebGPU:
const canvas = document.createElement('canvas');
const context = canvas.getContext('webgpu');
context.configure({
device,
format: presentationFormat,
});
canvas.width = numBins;
canvas.height = height;
document.body.appendChild(canvas);
y finalmente podemos renderizar:
// Obtener la textura actual del contexto del canvas y
// establecerla como la textura a la que renderizar.
const renderPassDescriptor = {
label: 'our basic canvas renderPass',
colorAttachments: [
{
view: context.getCurrentTexture().createView(),
clearValue: [0.3, 0.3, 0.3, 1],
loadOp: 'clear',
storeOp: 'store',
},
],
};
const encoder = device.createCommandEncoder({ label: 'render histogram' });
const pass = encoder.beginRenderPass(renderPassDescriptor);
pass.setPipeline(drawHistogramPipeline);
pass.setBindGroup(0, bindGroup);
pass.draw(6); // llamar a nuestro vertex shader 6 veces
pass.end();
const commandBuffer = encoder.finish();
device.queue.submit([commandBuffer]);
}
Y con todo eso, estamos renderizando en la GPU:
Hagamos una última cosa: obtengamos un histograma de un vídeo. Básicamente vamos a fusionar el ejemplo de el artículo sobre el uso de vídeo externo y nuestro ejemplo anterior.
Necesitamos actualizar nuestro HTML y CSS para que coincidan con el ejemplo del vídeo:
<style>
@import url(resources/webgpu-lesson.css);
+html, body {
+ margin: 0; /* eliminar el margen por defecto */
+ height: 100%; /* hacer que html,body llenen la página */
+}
canvas {
+ display: block; /* hacer que el canvas actúe como bloque */
+ width: 100%; /* hacer que el canvas llene su contenedor */
+ height: 100%;
- max-width: 256px;
- border: 1px solid #888;
}
+#start {
+ position: fixed;
+ left: 0;
+ top: 0;
+ width: 100%;
+ height: 100%;
+ display: flex;
+ justify-content: center;
+ align-items: center;
+}
+#start>div {
+ font-size: 200px;
+ cursor: pointer;
+}
</style>
</head>
<body>
+ <canvas></canvas>
+ <div id="start">
+ <div>▶️</div>
+ </div>
</body>
Configuraremos un canvas justo al principio:
// Obtener un contexto de WebGPU del canvas y configurarlo
const canvas = document.querySelector('canvas');
const context = canvas.getContext('webgpu');
const presentationFormat = navigator.gpu.getPreferredCanvasFormat();
context.configure({
device,
format: presentationFormat,
});
Como estamos usando una textura externa, necesitamos cambiar nuestros shaders para ese tipo de textura. Por ejemplo, el shader que crea los chunks del histograma necesita estos cambios:
const chunkSize = chunkWidth * chunkHeight;
var<workgroup> bins: array<array<atomic<u32>, 4>, chunkSize>;
@group(0) @binding(0) var<storage, read_write> chunks: array<array<vec4u, chunkSize>>;
-@group(0) @binding(1) var ourTexture: texture_2d<f32>;
+@group(0) @binding(1) var ourTexture: texture_external;
const kSRGBLuminanceFactors = vec3f(0.2126, 0.7152, 0.0722);
fn srgbLuminance(color: vec3f) -> f32 {
return saturate(dot(color, kSRGBLuminanceFactors));
}
@compute @workgroup_size(chunkWidth, chunkHeight, 1)
fn cs(
@builtin(workgroup_id) workgroup_id: vec3u,
@builtin(local_invocation_id) local_invocation_id: vec3u,
) {
- let size = textureDimensions(ourTexture, 0);
+ let size = textureDimensions(ourTexture);
let position = workgroup_id.xy * vec2u(chunkWidth, chunkHeight) +
local_invocation_id.xy;
if (all(position < size)) {
let numBins = f32(chunkSize);
let lastBinIndex = u32(numBins - 1);
- var channels = textureLoad(ourTexture, position, 0);
+ var channels = textureLoad(ourTexture, position);
channels.w = srgbLuminance(channels.rgb);
for (var ch = 0; ch < 4; ch++) {
let v = channels[ch];
let bin = min(u32(v * numBins), lastBinIndex);
atomicAdd(&bins[bin][ch], 1u);
}
}
...
Nuestro shader para calcular la escala tiene cambios similares:
@group(0) @binding(0) var<storage, read> bins: array<vec4u>;
@group(0) @binding(1) var<storage, read_write> scale: vec4f;
-@group(0) @binding(2) var ourTexture: texture_2d<f32>;
+@group(0) @binding(2) var ourTexture: texture_external;
@compute @workgroup_size(1, 1, 1) fn cs() {
- let size = textureDimensions(ourTexture, 0);
+ let size = textureDimensions(ourTexture);
let numEntries = f32(size.x * size.y);
...
El módulo de shader para dibujar el vídeo se copia directamente del artículo del vídeo, al igual que la creación de una pipeline de renderizado para usarlo, un sampler para el vídeo, un buffer de uniform y el render pass para dibujar. Tenemos el mismo código para esperar a un clic e iniciar la reproducción del vídeo.
Después de que el vídeo comience, podemos configurar el cálculo del histograma. El único cambio es que no obtenemos nuestro tamaño de la textura sino del vídeo.
- const imgBitmap = await loadImageBitmap('resources/images/pexels-francesco-ungaro-96938-mid.jpg');
- const texture = createTextureFromSource(device, imgBitmap);
- const chunksAcross = Math.ceil(texture.width / k.chunkWidth);
- const chunksDown = Math.ceil(texture.height / k.chunkHeight);
+ const chunksAcross = Math.ceil(video.videoWidth / k.chunkWidth);
+ const chunksDown = Math.ceil(video.videoHeight / k.chunkHeight);
Teníamos nuestro código para dibujar los histogramas en drawHistogram, pero ese código creaba su propio canvas y otras cosas que solo se usaban una vez. Nos desharemos de drawHistogram y crearemos código para configurar un buffer de uniform y un bind group para cada uno de los 2 histogramas que queremos dibujar:
const histogramDrawInfos = [
[0, 1, 2],
[3],
].map(channels => {
// matrix: mat4x4f;
// colors: array<vec4f, 16>;
// channelMult: vec4u;
const uniformValuesAsF32 = new Float32Array(16 + 64 + 4 + 4);
const uniformValuesAsU32 = new Uint32Array(uniformValuesAsF32.buffer);
const uniformBuffer = device.createBuffer({
label: 'draw histogram uniform buffer',
size: uniformValuesAsF32.byteLength,
usage: GPUBufferUsage.UNIFORM | GPUBufferUsage.COPY_DST,
});
thingsToDestroy.push(uniformBuffer);
const subpart = (view, offset, length) => view.subarray(offset, offset + length);
const matrix = subpart(uniformValuesAsF32, 0, 16);
const colors = subpart(uniformValuesAsF32, 16, 64);
const channelMult = subpart(uniformValuesAsU32, 16 + 64, 4);
colors.set([
[0, 0, 0, 1],
[1, 0, 0, 1],
[0, 1, 0, 1],
[1, 1, 0, 1],
[0, 0, 1, 1],
[1, 0, 1, 1],
[0, 1, 1, 1],
[0.5, 0.5, 0.5, 1],
[1, 1, 1, 1],
[1, 1, 1, 1],
[1, 1, 1, 1],
[1, 1, 1, 1],
[1, 1, 1, 1],
[1, 1, 1, 1],
[1, 1, 1, 1],
[1, 1, 1, 1],
].flat());
const drawHistogramBindGroup = device.createBindGroup({
layout: drawHistogramPipeline.getBindGroupLayout(0),
entries: [
{ binding: 0, resource: { buffer: chunksBuffer, size: chunkSize * 4 * 4 }},
{ binding: 1, resource: uniformBuffer },
{ binding: 2, resource: scaleBuffer },
],
});
return {
drawHistogramBindGroup,
matrix,
uniformBuffer,
uniformValuesAsF32,
};
});
En el momento del renderizado, primero importamos la textura del vídeo. Recuerda que solo es válida para este único evento de JavaScript, por lo que tenemos que crear los bind groups que referencian la textura en cada frame:
function render() {
const texture = device.importExternalTexture({source: video});
// crear un bind group para generar un histograma a partir de esta textura de vídeo
const histogramBindGroup = device.createBindGroup({
layout: histogramChunkPipeline.getBindGroupLayout(0),
entries: [
{ binding: 0, resource: chunksBuffer },
{ binding: 1, resource: texture },
],
});
const scaleBindGroup = device.createBindGroup({
layout: scalePipeline.getBindGroupLayout(0),
entries: [
{ binding: 0, resource: { buffer: chunksBuffer, size: chunkSize * 4 * 4 }},
{ binding: 1, resource: scaleBuffer },
{ binding: 2, resource: texture },
],
});
... insertar código de cálculo del histograma aquí ...
En cuanto al renderizado, renderizar el vídeo es similar al artículo sobre renderizado de vídeo externo. La única diferencia es el código que calcula la matriz. Estamos escalando por 2 y restando 1 como mencionamos arriba para el histograma, pero estamos usando -2 para la Y y sumando 1 para que se invierta la Y. También estamos escalando para obtener un efecto de cobertura de modo que el vídeo siempre llene el canvas manteniendo la relación de aspecto correcta.
// Dibujar en el canvas
{
const canvasTexture = context.getCurrentTexture().createView();
renderPassDescriptor.colorAttachments[0].view = canvasTexture;
const pass = encoder.beginRenderPass(renderPassDescriptor);
// Dibujar vídeo
const bindGroup = device.createBindGroup({
layout: videoPipeline.getBindGroupLayout(0),
entries: [
{ binding: 0, resource: videoSampler },
{ binding: 1, resource: texture },
{ binding: 2, resource: videoUniformBuffer },
],
});
// 'cubrir' (cover) el canvas
const canvasAspect = canvas.clientWidth / canvas.clientHeight;
const videoAspect = video.videoWidth / video.videoHeight;
const scale = canvasAspect > videoAspect
? [1, canvasAspect / videoAspect, 1]
: [videoAspect / canvasAspect, 1, 1];
const matrix = mat4.identity(videoMatrix);
mat4.scale(matrix, scale, matrix);
mat4.translate(matrix, [-1, 1, 0], matrix);
mat4.scale(matrix, [2, -2, 1], matrix);
device.queue.writeBuffer(videoUniformBuffer, 0, videoUniformValues);
pass.setPipeline(videoPipeline);
pass.setBindGroup(0, bindGroup);
pass.draw(6); // llamar a nuestro vertex shader 6 veces
Para dibujar los histogramas simplemente movemos el código de drawHistogram:
// Dibujar Histogramas
histogramDrawInfos.forEach(({
matrix,
uniformBuffer,
uniformValuesAsF32,
drawHistogramBindGroup,
}, i) => {
mat4.identity(matrix);
mat4.translate(matrix, [-0.95 + i, -1, 0], matrix);
mat4.scale(matrix, [0.9, 0.5, 1], matrix);
device.queue.writeBuffer(uniformBuffer, 0, uniformValuesAsF32);
pass.setPipeline(drawHistogramPipeline);
pass.setBindGroup(0, drawHistogramBindGroup);
pass.draw(6); // llamar a nuestro vertex shader 6 veces
});
pass.end();
}
const commandBuffer = encoder.finish();
device.queue.submit([commandBuffer]);
requestAnimationFrame(render);
}
requestAnimationFrame(render);
Las matemáticas de matrices anteriores dibujan un quad a la izquierda o derecha que tiene el 90% del ancho de la mitad del canvas, centrado en esa mitad, y ¼ de la altura del canvas.
Bien, entonces, ¿por qué calcular un histograma? Hay varias cosas que puedes hacer con un histograma:
- mostrarlo al usuario para que pueda tomar decisiones informadas sobre los ajustes de la imagen.
- aplicar una ecualización de histograma a la imagen.
- aplicar una ecualización de histograma adaptativa a la imagen.
- usarlo para la segmentación de imágenes.
- posterizar usando umbralización por histograma.
Y un montón de otras técnicas. Quizás podamos cubrir algunas más adelante. Mi esperanza es que estos ejemplos hayan sido útiles. Pasamos de un JavaScript que calculaba y dibujaba un histograma a tener todo el trabajo hecho en la GPU, incluyendo el renderizado, que esperamos sea lo suficientemente rápido como para ejecutarse en tiempo real.