Modo de compatibilidad de WebGPU
El modo de compatibilidad de WebGPU (WebGPU Compatibility mode) es una versión de WebGPU que, con algunos límites, puede ejecutarse en dispositivos más antiguos. La idea es que, si puedes hacer que tu aplicación funcione dentro de algunos límites y restricciones adicionales, entonces puedes solicitar un adaptador de compatibilidad de WebGPU y hacer que tu aplicación funcione en más lugares.
Nota: El modo de compatibilidad se lanza en Chrome 146 (2026-02-23). Es posible que esté disponible en tu navegador como experimento. En Chrome Canary, a partir de la versión 136.0.7063.0 (2025-03-11), puedes permitir el modo de compatibilidad habilitando el flag “enable-unsafe-webgpu” yendo a
chrome://flags/#enable-unsafe-webgpu.
Para dar una idea de lo que puedes hacer en el modo de compatibilidad, efectivamente casi todos los programas de WebGL2 podrían convertirse para ejecutarse en el modo de compatibilidad.
Aquí tienes cómo hacerlo:
const adapter = await navigator.gpu.requestAdapter({
featureLevel: 'compatibility',
});
const device = await adapter.requestDevice();
¡Simple! Ten en cuenta que cualquier aplicación que siga todos los límites del modo de compatibilidad es una aplicación “core” de WebGPU válida y funcionará en cualquier lugar donde WebGPU ya esté funcionando.
Principales límites y restricciones
Posiblemente 0 storage buffers en vertex shaders.
La restricción principal que es más probable que afecte a las aplicaciones WebGPU es que aproximadamente el 45% de estos dispositivos antiguos no admiten storage buffers (buffers de almacenamiento) en los vertex shaders (shaders de vértices).
Usamos esta característica en el artículo sobre storage buffers, que es el tercer artículo de este sitio. Después de ese artículo, cambiamos a usar vertex buffers. Usar vertex buffers (buffers de vértices) es común y funciona en todas partes, pero ciertas soluciones son más fáciles con storage buffers. Un ejemplo es este ejemplo de dibujo de wireframes. Utiliza storage buffers para generar triángulos a partir de datos de vértices.
Con los datos de vértices almacenados en storage buffers, podemos acceder aleatoriamente a los datos de los vértices. Con los datos de vértices en un vertex buffer, no podemos. Por supuesto, siempre hay otras soluciones.
Límites y restricciones de nivel medio
Solo se permite una única dimensión de vista para una textura como TEXTURE_BINDING
En WebGPU normal, puedes crear una textura 2D así:
const miTextura = device.createTexture({
size: [ancho, alto, 6],
usage: ...
format: ...
});
Luego puedes verla con 3 dimensiones de vista diferentes:
// una vista de miTextura como un array 2D con 6 capas
const comoArray2D = miTextura.createView();
// ver la capa 3 de miTextura como una textura 2D
const como2D = miTextura.createView({
dimension: '2d',
baseArrayLayer: 3,
arrayLayerCount: 1,
});
// vista de miTextura como un cubemap (mapa de cubo)
const comoCube = miTextura.createView({
dimension: 'cube',
});
En el modo de compatibilidad, solo puedes usar una dimensión de vista y tienes que
elegir qué dimensión de vista al crear la textura. Una textura 2D con
1 capa por defecto solo se puede usar como una vista '2d'. Una textura 2D con
más de 1 capa por defecto solo se puede usar como una vista '2d-array'.
Si quieres algo diferente al valor por defecto, debes indicárselo a WebGPU. Por ejemplo,
si quieres un cubemap, debes decírselo a WebGPU cuando crees la textura.
const cubeTexture = device.createTexture({
size: [ancho, alto, 6],
usage: ...
format: ...
textureBindingViewDimension: 'cube',
});
Nota: este parámetro adicional se llama textureBindingViewDimension porque
se refiere al uso de la textura con el uso TEXTURE_BINDING. Aún puedes
usar una sola capa de un cubemap o de un array 2D como una textura 2D como RENDER_ATTACHMENT.
Dicho de otra manera, debes usar esta misma dimensión de vista al usar la
textura en un bind group. Todavía puedes usar la dimensión 2d, incluso si la
textureBindingViewDimension es 2d-array o cube, cuando uses la textura
como un objetivo de renderizado (render target).
En el modo de compatibilidad, usar la textura en un bind group con otro tipo de vista generará un error de validación.
// una vista de cubeTexture como un array 2D con 6 capas
const bindGroup = device.createBindGroup({
...
entries: [
{
binding,
// ERROR en modo de compatibilidad: la textura es un cubemap, no un array 2D
// (el valor por defecto para una textura con más de 1 capa)
resource: cubeTexture,
},
],
})
// ver la capa 3 de cubeTexture como una textura 2D
const bindGroup = device.createBindGroup({
...
entries: [
{
binding,
// ERROR en modo de compatibilidad: la textura es un cubemap, no 2D
resource: cubeTexture.createView({
viewDimension: '2d',
baseArrayLayer: 3,
arrayLayerCount: 1,
}),
},
]
});
// vista de cubeTexture como un cubemap
const bindGroup = device.createBindGroup({
...
entries: [
{
binding,
// ¡BIEN!
resource: cubeTexture.createView({
viewDimension: 'cube',
}),
},
],
});
Esta restricción no es para tanto. Pocos programas quieren usar una textura con diferentes tipos de vistas.
Al llamar a texture.createView, no puedes seleccionar un subconjunto de capas en un bindGroup
En el núcleo (core) de WebGPU, podemos crear una textura con algunas capas:
const textura = device.createTexture({
size: [64, 128, 8], // 8 capas,
...
});
Luego podemos seleccionar un subconjunto de capas:
const bindGroup = device.createBindGroup({
...
entries: [
{
binding,
// ERROR en modo de compatibilidad - seleccionar capas 3 y 4
resource: cubeTexture.createView({
baseArrayLayer: 3,
arrayLayerCount: 2,
}),
},
],
});
Esta restricción tampoco es para tanto. Pocos programas quieren seleccionar un subconjunto de capas de una textura.
Generar mipmaps en modo de compatibilidad.
Sin embargo, hay un lugar donde aparecen ambas restricciones: al generar mipmaps, que es un caso de uso común.
Recuerda que creamos un generador de mipmaps basado en GPU en
el artículo sobre la importación de imágenes en texturas.
Modificamos esa función para generar mipmaps para arrays 2D y cubemaps en
el artículo sobre cube maps. En esa versión,
siempre vemos cada capa de la textura con una dimensión '2d' para referenciar
solo una capa de la textura.
Esto no funcionará en el modo de compatibilidad por las razones mencionadas anteriormente. No podemos usar una vista
'2d' de una textura '2d-array' o 'cube'. Tampoco podemos seleccionar capas individuales
en un bind group para elegir de qué capa leer.
Para que el código funcione en el modo de compatibilidad, tenemos que trabajar con texturas
con la misma dimensión de vista con la que fueron creadas, y necesitamos pasar la textura
con acceso a todas las capas y seleccionar la capa que queremos en el propio shader, en lugar
de seleccionar la capa a través de createView como estábamos haciendo.
¡Así que hagámoslo! Empezaremos con el código de generateMips del artículo sobre cubemaps.
const generateMips = (() => {
let sampler;
let module;
const pipelineByFormat = {};
return function generateMips(device, texture) {
if (!module) {
module = device.createShaderModule({
label: 'textured quad shaders for mip level generation',
code: /* wgsl */ `
struct VSOutput {
@builtin(position) position: vec4f,
@location(0) texcoord: vec2f,
};
@vertex fn vs(
@builtin(vertex_index) vertexIndex : u32
) -> VSOutput {
let pos = array(
vec2f( 0.0, 0.0), // centro
vec2f( 1.0, 0.0), // derecha, centro
vec2f( 0.0, 1.0), // centro, arriba
// 2do triángulo
vec2f( 0.0, 1.0), // centro, arriba
vec2f( 1.0, 0.0), // derecha, centro
vec2f( 1.0, 1.0), // derecha, arriba
);
var vsOutput: VSOutput;
let xy = pos[vertexIndex];
vsOutput.position = vec4f(xy * 2.0 - 1.0, 0.0, 1.0);
vsOutput.texcoord = vec2f(xy.x, 1.0 - xy.y);
return vsOutput;
}
@group(0) @binding(0) var ourSampler: sampler;
@group(0) @binding(1) var ourTexture: texture_2d<f32>;
@fragment fn fs(fsInput: VSOutput) -> @location(0) vec4f {
return textureSample(ourTexture, ourSampler, fsInput.texcoord);
}
`,
});
sampler = device.createSampler({
minFilter: 'linear',
magFilter: 'linear',
});
}
if (!pipelineByFormat[texture.format]) {
pipelineByFormat[texture.format] = device.createRenderPipeline({
label: 'mip level generator pipeline',
layout: 'auto',
vertex: {
module,
},
fragment: {
module,
targets: [{ format: texture.format }],
},
});
}
const pipeline = pipelineByFormat[texture.format];
const encoder = device.createCommandEncoder({
label: 'mip gen encoder',
});
for (let baseMipLevel = 1; baseMipLevel < texture.mipLevelCount; ++baseMipLevel) {
for (let layer = 0; layer < texture.depthOrArrayLayers; ++layer) {
const bindGroup = device.createBindGroup({
layout: pipeline.getBindGroupLayout(0),
entries: [
{ binding: 0, resource: sampler },
{
binding: 1,
resource: texture.createView({
dimension: '2d',
baseMipLevel: baseMipLevel - 1,
mipLevelCount: 1,
baseArrayLayer: layer,
arrayLayerCount: 1,
}),
},
],
});
const renderPassDescriptor = {
label: 'our basic canvas renderPass',
colorAttachments: [
{
view: texture.createView({
dimension: '2d',
baseMipLevel: baseMipLevel,
mipLevelCount: 1,
baseArrayLayer: layer,
arrayLayerCount: 1,
}),
loadOp: 'clear',
storeOp: 'store',
},
],
};
const pass = encoder.beginRenderPass(renderPassDescriptor);
pass.setPipeline(pipeline);
pass.setBindGroup(0, bindGroup);
pass.draw(6); // llama a nuestro vertex shader 6 veces
pass.end();
}
}
const commandBuffer = encoder.finish();
device.queue.submit([commandBuffer]);
};
})();
Necesitamos cambiar el WGSL para que, para cada tipo de textura (2d, 2d-array, cube, etc.), usemos un fragment shader diferente y necesitemos poder pasar una capa desde la que leer.
const faceMat = array(
mat3x3f( 0, 0, -2, 0, -2, 0, 1, 1, 1), // pos-x
mat3x3f( 0, 0, 2, 0, -2, 0, -1, 1, -1), // neg-x
mat3x3f( 2, 0, 0, 0, 0, 2, -1, 1, -1), // pos-y
mat3x3f( 2, 0, 0, 0, 0, -2, -1, -1, 1), // neg-y
mat3x3f( 2, 0, 0, 0, -2, 0, -1, 1, 1), // pos-z
mat3x3f(-2, 0, 0, 0, -2, 0, 1, 1, -1)); // neg-z
struct VSOutput {
@builtin(position) position: vec4f,
@location(0) texcoord: vec2f,
@location(1) @interpolate(flat, either) baseArrayLayer: u32,
};
@vertex fn vs(
@builtin(vertex_index) vertexIndex : u32,
@builtin(instance_index) baseArrayLayer: u32,
) -> VSOutput {
var pos = array<vec2f, 3>(
vec2f(-1.0, -1.0),
vec2f(-1.0, 3.0),
vec2f( 3.0, -1.0),
);
var vsOutput: VSOutput;
let xy = pos[vertexIndex];
vsOutput.position = vec4f(xy, 0.0, 1.0);
vsOutput.texcoord = xy * vec2f(0.5, -0.5) + vec2f(0.5);
vsOutput.baseArrayLayer = baseArrayLayer;
return vsOutput;
}
@group(0) @binding(0) var ourSampler: sampler;
@group(0) @binding(1) var ourTexture2d: texture_2d<f32>;
@fragment fn fs2d(fsInput: VSOutput) -> @location(0) vec4f {
return textureSample(ourTexture2d, ourSampler, fsInput.texcoord);
}
@group(0) @binding(1) var ourTexture2dArray: texture_2d_array<f32>;
@fragment fn fs2darray(fsInput: VSOutput) -> @location(0) vec4f {
return textureSample(
ourTexture2dArray,
ourSampler,
fsInput.texcoord,
fsInput.baseArrayLayer);
}
@group(0) @binding(1) var ourTextureCube: texture_cube<f32>;
@fragment fn fscube(fsInput: VSOutput) -> @location(0) vec4f {
return textureSample(
ourTextureCube,
ourSampler,
faceMat[fsInput.baseArrayLayer] * vec3f(fract(fsInput.texcoord), 1));
}
Este código tiene 3 fragment shaders, uno para cada una de las dimensiones: '2d', '2d-array', 'cube'.
Utiliza la técnica del triángulo grande para cubrir el espacio de recorte
tratada en otro lugar para dibujar.
También utiliza @builtin(instance_index) para seleccionar la capa. Esta es una forma interesante y rápida
de pasar un único valor entero a un shader sin tener que usar un uniform buffer.
Cuando llamamos a draw, el cuarto parámetro es la primera instancia (firstInstance), que se pasará
al shader como @builtin(instance_index). Pasamos eso del vertex shader al fragment
shader a través de VSOutput.baseArrayLayer, que podemos referenciar como fsInput.baseArrayLayer
en el fragment shader.
El código del cubemap convierte una capa de un array 2D y una coordenada UV normalizada en una coordenada 3D de cubemap. Necesitamos esto porque, de nuevo, en el modo de compatibilidad, un cubemap solo se puede ver como un cubemap.
Volviendo a nuestro JavaScript, necesitamos leer la propiedad textureBindingViewDimension
de la textura. Ten en cuenta que este valor es undefined si no estamos en el modo de
compatibilidad. Pero podemos simplemente asumir '2d-array' en ese caso, ya que en el WebGPU “core” normal,
'2d-array' siempre debería funcionar.
const generateMips = (() => {
let sampler;
let module;
const pipelineByFormat = {};
return function generateMips(device, texture) {
// Si la textura no tiene una textureBindingViewDimension, usar '2d-array'
const textureBindingViewDimension = texture.textureBindingViewDimension ?? '2d-array';
if (!module) {
module = device.createShaderModule({
label: 'textured quad shaders for mip level generation',
code: /* wgsl */ `
const faceMat = array(
mat3x3f( 0, 0, -2, 0, -2, 0, 1, 1, 1), // pos-x
mat3x3f( 0, 0, 2, 0, -2, 0, -1, 1, -1), // neg-x
mat3x3f( 2, 0, 0, 0, 0, 2, -1, 1, -1), // pos-y
mat3x3f( 2, 0, 0, 0, 0, -2, -1, -1, 1), // neg-y
mat3x3f( 2, 0, 0, 0, -2, 0, -1, 1, 1), // pos-z
mat3x3f(-2, 0, 0, 0, -2, 0, 1, 1, -1)); // neg-z
struct VSOutput {
@builtin(position) position: vec4f,
@location(0) texcoord: vec2f,
@location(1) @interpolate(flat, either) baseArrayLayer: u32,
};
@vertex fn vs(
@builtin(vertex_index) vertexIndex : u32,
@builtin(instance_index) baseArrayLayer: u32,
) -> VSOutput {
var pos = array<vec2f, 3>(
vec2f(-1.0, -1.0),
vec2f(-1.0, 3.0),
vec2f( 3.0, -1.0),
);
var vsOutput: VSOutput;
let xy = pos[vertexIndex];
vsOutput.position = vec4f(xy, 0.0, 1.0);
vsOutput.texcoord = xy * vec2f(0.5, -0.5) + vec2f(0.5);
vsOutput.baseArrayLayer = baseArrayLayer;
return vsOutput;
}
@group(0) @binding(0) var ourSampler: sampler;
@group(0) @binding(1) var ourTexture2d: texture_2d<f32>;
@fragment fn fs2d(fsInput: VSOutput) -> @location(0) vec4f {
return textureSample(ourTexture2d, ourSampler, fsInput.texcoord);
}
@group(0) @binding(1) var ourTexture2dArray: texture_2d_array<f32>;
@fragment fn fs2darray(fsInput: VSOutput) -> @location(0) vec4f {
return textureSample(
ourTexture2dArray,
ourSampler,
fsInput.texcoord,
fsInput.baseArrayLayer);
}
@group(0) @binding(1) var ourTextureCube: texture_cube<f32>;
@fragment fn fscube(fsInput: VSOutput) -> @location(0) vec4f {
return textureSample(
ourTextureCube,
ourSampler,
faceMat[fsInput.baseArrayLayer] * vec3f(fract(fsInput.texcoord), 1));
}
`,
});
sampler = device.createSampler({
minFilter: 'linear',
magFilter: 'linear',
});
}
...
Antes hacíamos el seguimiento de un pipeline por cada formato, de modo que podíamos reutilizar el pipeline para
texturas del mismo formato. Necesitamos actualizar eso para que sea un pipeline por formato
y por viewDimension.
const generateMips = (() => {
let sampler;
let module;
const pipelineByFormatAndView = {};
return function generateMips(device, texture, textureBindingViewDimension) {
// Si la textura no tiene una textureBindingViewDimension, usar '2d-array'.
// Esto será true en el modo webgpu core.
const textureBindingViewDimension = texture.textureBindingViewDimension ?? '2d-array';
let module = moduleByViewDimension[textureBindingViewDimension];
if (!module) {
...
}
const id = `${texture.format}.${textureBindingViewDimension}`;
if (!pipelineByFormatAndView[id]) {
// elegir un fragment shader basado en el viewDimension (elimina el '-' de 2d-array y cube-array)
const entryPoint = `fs${textureBindingViewDimension.replace(/[\W]/, '')}`;
pipelineByFormatAndView[id] = device.createRenderPipeline({
label: `mip level generator pipeline for ${textureBindingViewDimension}, format: ${texture.format}`,
layout: 'auto',
vertex: {
module,
},
fragment: {
module,
entryPoint,
targets: [{ format: texture.format }],
},
});
}
const pipeline = pipelineByFormatAndView[id];
...
}
Luego, nuestro bucle para generar el mipmap debe cambiar para usar las capas completas, ya que
el modo de compatibilidad no permite un subrango de capas. También necesitamos usar
nuestra capacidad de pasar el índice de instancia a través de draw para seleccionar la capa de la que queremos leer.
const generateMips = (() => {
...
const pipeline = pipelineByFormatAndView[id];
for (let baseMipLevel = 1; baseMipLevel < texture.mipLevelCount; ++baseMipLevel) {
for (let layer = 0; layer < texture.depthOrArrayLayers; ++layer) {
const bindGroup = device.createBindGroup({
layout: pipeline.getBindGroupLayout(0),
entries: [
{ binding: 0, resource: sampler },
{
binding: 1,
resource: texture.createView({
dimension: textureBindingViewDimension,
baseMipLevel: baseMipLevel - 1,
mipLevelCount: 1,
}),
},
],
});
const renderPassDescriptor = {
label: 'our basic canvas renderPass',
colorAttachments: [
{
view: texture.createView({
dimension: '2d',
baseMipLevel,
mipLevelCount: 1,
baseArrayLayer: layer,
arrayLayerCount: 1,
}),
loadOp: 'clear',
storeOp: 'store',
},
],
};
const pass = encoder.beginRenderPass(renderPassDescriptor);
pass.setPipeline(pipeline);
pass.setBindGroup(0, bindGroup);
// dibujar 3 vértices, 1 instancia, primera instancia (instance_index) = layer
pass.draw(3, 1, 0, layer);
pass.end();
}
}
const commandBuffer = encoder.finish();
device.queue.submit([commandBuffer]);
};
})();
Con eso, nuestro código de generación de mipmaps funciona en el modo de compatibilidad, y sigue funcionando en el núcleo de WebGPU.
Sin embargo, tenemos algunas otras cosas que actualizar para que el ejemplo funcione.
Tenemos una función createTextureFromSources a la que le pasamos orígenes (sources)
y crea una textura. Siempre creaba una textura '2d',
ya que en el modo core podemos ver una textura '2d' con 6 capas como un cubemap.
En su lugar, necesitamos hacer que podamos pasar una textureBindingViewDimension y/o
una dimensión para que, cuando creemos la textura, podamos indicarle al modo de
compatibilidad cómo la veremos.
function textureViewDimensionToDimension(viewDimension) {
switch (viewDimension) {
case '1d': return '1d';
case '3d': return '3d';
default: return '2d';
}
}
function createTextureFromSources(device, sources, options = {}) {
const viewDimension = options.dimension ??
getDefaultViewDimensionForTexture(options.textureBindingViewDimension);
const dimension = options.dimension ?? textureViewDimensionToDimension(viewDimension);
// Asumir que todos los orígenes tienen el mismo tamaño, así que solo usamos el primero para el ancho y el alto
const source = sources[0];
const texture = device.createTexture({
format: 'rgba8unorm',
mipLevelCount: options.mips ? numMipLevels(source.width, source.height) : 1,
size: [source.width, source.height, sources.length],
usage: GPUTextureUsage.TEXTURE_BINDING |
GPUTextureUsage.COPY_DST |
GPUTextureUsage.RENDER_ATTACHMENT,
dimension,
textureBindingViewDimension: options.textureBindingViewDimension,
});
copySourcesToTexture(device, texture, sources, options);
return texture;
}
Y necesitamos actualizar nuestra llamada a createTextureFromSources para indicarle de antemano
que queremos un cubemap.
const texture = await createTextureFromSources(
device, faceCanvases, {mips: true, flipY: false, textureBindingViewDimension: 'cube'});
Para que el ejemplo se ejecute en el modo de compatibilidad, debemos solicitarlo como explicamos al principio de este artículo.
async function main() {
const adapter = await navigator.gpu?.requestAdapter({
featureLevel: 'compatibility',
});
const device = await adapter?.requestDevice();
...
Y con eso, nuestro ejemplo de cube map funciona en el modo de compatibilidad.
Ahora tienes una función generateMips amigable con el modo de compatibilidad que podrías
usar en cualquiera de los ejemplos de este sitio. Funciona tanto en el modo core como en el de compatibilidad.
En el modo de compatibilidad debes pasar una textureBindingViewDimension si quieres un cube map o si
quieres un array 2D de 1 capa. En el núcleo de WebGPU puedes pasar una o no; no importa.
Restricciones y límites menores
Los siguientes son límites y restricciones con los que es poco probable que se topen la mayoría de los programas:
-
El blending de color debe coincidir en todos los color targets.
En el modo core, cuando creas un render pipeline, cada color target (objetivo de color) puede especificar ajustes de blending (mezcla). Usamos ajustes de blending en el artículo sobre blending y transparencia. En el modo de compatibilidad, todos los ajustes en todos los color targets de un mismo pipeline deben ser iguales.
-
copyTextureToBufferycopyTextureToTextureno funcionan con texturas comprimidas. -
copyTextureToTextureno funciona con texturas multisampleadas (multisampled). -
cube-arrayno está admitido. -
Las vistas de una textura no pueden diferir en aspecto o niveles de mip en una sola llamada de draw/dispatch.
En el núcleo de WebGPU, puedes crear múltiples vistas de una textura para diferentes niveles de mip Y usarlas en la misma llamada de dibujo. Esto es poco común. Ten en cuenta que esta restricción se aplica al uso de
TEXTURE_BINDING, es decir, al usar una textura a través de un bindGroup. Todavía puedes usar una vista diferente comoRENDER_ATTACHMENT, como hicimos en el código de generación de mipmaps anterior. -
@builtin(sample_mask)y@builtin(sample_index)no están admitidos. -
Los formatos de textura
rg32uint,rg32sintyrg32floatno pueden usarse como storage textures (texturas de almacenamiento). -
depthClampBiasdebe ser 0.Este es un ajuste que se utiliza al crear un render pipeline.
-
@interpolation(linear)y@interpolation(..., sample)no están admitidos.Estos se mencionaron brevemente en el artículo sobre variables entre etapas.
-
@interpolate(flat)y@interpolate(flat, first)no están admitidos.En el modo de compatibilidad debes usar
@interpolate(flat, either)cuando quieras interpolación plana (flat).eithersignifica que el valor pasado al fragment shader podría ser el valor del primer o del último vértice del triángulo o línea que se está dibujando. Depende de la implementación.Es habitual que esto no importe. Los casos de uso más comunes para pasar algo con interpolación plana del vertex shader al fragment shader suelen ser valores de tipo por modelo, por material o por instancia. Por ejemplo, el código de generación de mipmaps anterior usó interpolación plana para pasar el
instance_indexal fragment shader. Será el mismo para todos los vértices de un triángulo y, por tanto, funciona perfectamente con@interpolate(flat, either). -
Los formatos de textura no pueden ser reinterpretados.
En el núcleo de WebGPU, puedes crear una textura
'rgba8unorm'y verla como una textura'rgba8unorm-srgb'y viceversa, así como otros formatos'-srgb'y sus correspondientes formatos que no son'-srgb'. El modo de compatibilidad no permite esto. El formato en que creas la textura es el único formato con el que se puede usar. -
bgra8unorm-srgbno está admitido. -
Las texturas
rgba16floatyr32floatno pueden ser multisampleadas. -
Todos los formatos de textura de enteros no pueden ser multisampleados.
-
depthOrArrayLayersdebe ser compatible contextureBindingViewDimension.Esto significa que una textura marcada con
textureBindingViewDimension: '2d'debe tener undepthOrArrayLayers: 1(el valor por defecto). Una textura marcada contextureBindingViewDimension: 'cube'debe tenerdepthOrArrayLayers: 6. -
textureLoadno funciona con texturas de profundidad (depth textures).Una “textura de profundidad” es una textura referenciada en WGSL con
texture_depth,texture_depth_2d_arrayotexture_depth_cube. Estas no pueden usarse contextureLoaden el modo de compatibilidad.Por otro lado,
textureLoadpuede usarse contexture_2d<f32>,texture_2d_array<f32>ytexture_cube<f32>, y una textura que tenga un formato de profundidad puede vincularse a estos bindings. -
Las texturas de profundidad no pueden usarse con samplers que no sean de comparación.
De nuevo, una “textura de profundidad” es una textura referenciada en WGSL con
texture_depth,texture_depth_2d_arrayotexture_depth_cube. Estas no pueden usarse con un sampler que no sea de comparación en el modo de compatibilidad.Esto significa efectivamente que
texture_depth,texture_depth_2d_arrayytexture_depth_cubesolo pueden usarse contextureSampleCompare,textureSampleCompareLevelytextureGatherCompareen el modo de compatibilidad.Por otro lado, puedes vincular una textura que use un formato de profundidad a un binding de
texture_2d<f32>,texture_2d_array<f32>ytexture_cube<f32>, sujeto a la restricción normal de que debe usar un sampler sin filtrado (non-filtering sampler). -
Las derivadas finas (fine derivatives) no están admitidas.
Las funciones de WGSL
dpdxFine,dpdyFineyfwidthFineno están admitidas en el modo de compatibilidad. Aún puedes usardpdx,dpdxCoarse,dpdy,dpdyCoarse,fwidthyfwidthCoarse. -
Las combinaciones de textura + sampler están más limitadas.
En el modo core, puedes vincular más de 16 texturas y más de 16 samplers y luego, en tu shader, puedes usar todas las más de 256 combinaciones.
En el modo de compatibilidad, solo puedes usar 16 combinaciones en total en una sola etapa.
La regla real es un poco más complicada. Aquí se detalla en pseudocódigo:
maxCombinacionesPorEtapa = min(device.limits.maxSampledTexturesPerShaderStage, device.limits.maxSamplersPerShaderStage) para cada etapa del pipeline: suma = 0 para cada binding de textura en el pipeline layout que sea visible para esa etapa: suma += max(1, número de combinaciones de textura y sampler para ese binding de textura) para cada binding de textura externa en el pipeline layout que sea visible para esa etapa: suma += 1 // para textura LUT + sampler LUT suma += 3 * max(1, número de combinaciones de external_texture y sampler) // para Y+U+V si suma > maxCombinacionesPorEtapa generar un error de validación. -
Algunos de los límites por defecto son más bajos en el modo de compatibilidad
límite compat núcleo (core) maxColorAttachments4 8 maxComputeInvocationsPerWorkgroup128 256 maxComputeWorkgroupSizeX128 256 maxComputeWorkgroupSizeY128 256 maxInterStageShaderVariables15 16 maxTextureDimension1D4096 8192 maxTextureDimension2D4096 8192 maxUniformBufferBindingSize16384 65536 maxVertexAttributes16a 16 (a) En el modo de compatibilidad, usar
@builtin(vertex_index)y/o@builtin(instance_index)cuenta cada uno como un atributo.Por supuesto, el adaptador puede admitir límites más altos para cualquiera de estos.
-
Hay 4 nuevos límites.
maxStorageBuffersInVertexStage(por defecto 0)maxStorageTexturesInVertexStage(por defecto 0)maxStorageBuffersInFragmentStage(por defecto 4)maxStorageTexturesInFragmentStage(por defecto 4)
Como con otros límites, puedes verificar qué admite el adaptador cuando solicites uno y requerir valores más altos que los predeterminados si necesitas más.
Como se mencionó anteriormente, aproximadamente el 45% de los dispositivos admiten
0storage buffers y storage textures (texturas de almacenamiento) en los vertex shaders.
Actualizar del modo de compatibilidad al modo core
El modo de compatibilidad fue diseñado para que tú elijas usarlo (opt-in). Si puedes diseñar tu aplicación para que conviva con las restricciones anteriores, entonces solicitas el modo de compatibilidad. Si no, solicitas el modo core (el predeterminado); si el dispositivo no puede manejar el modo core, no devolverá un adaptador.
Por otro lado, también puedes diseñar tu aplicación para que funcione en el modo de compatibilidad, pero aproveche todas las características del núcleo (core) si el usuario tiene un dispositivo que admita WebGPU core.
Para hacerlo, solicita un adaptador de modo de compatibilidad y luego verifica
y habilita la característica core-features-and-limits. Si
existe en el adaptador Y la requieres en el dispositivo, el
dispositivo será un dispositivo core y ninguna de las restricciones anteriores
se aplicará.
Ejemplo:
const adapter = await navigator.gpu.requestAdapter({
featureLevel: 'compatibility',
});
const tieneCore = adapter.features.has('core-features-and-limits');
const device = await adapter.requestDevice({
requiredFeatures: [
...(tieneCore ? ['core-features-and-limits'] : []),
],
});
Si tieneCore es true, entonces no se aplicará ninguna de las restricciones y límites anteriores.
Ten en cuenta que otro código que quiera verificar si el dispositivo es core o de
compatibilidad debe verificar las características (features) del dispositivo.
const esCore = device.features.has('core-features-and-limits');
Esto siempre será true en un dispositivo core.
Probar el modo de compatibilidad
En un navegador que admita el modo de compatibilidad, puedes probar si tu
aplicación sigue las restricciones NO solicitando 'core-features-and-limits' (como hicimos al principio).
Es posible que quieras verificar que realmente tienes un dispositivo de
compatibilidad para saber que las restricciones y los límites se están
aplicando.
const adapter = await navigator.gpu.requestAdapter({
featureLevel: 'compatibility',
});
const device = await adapter.requestDevice();
const esModoCompatibilidad = !device.features.has('core-features-and-limits');
Esta es una buena forma de probar si tu aplicación funcionará en estos dispositivos más antiguos.
Prueba rápida mediante webgpu-dev-extension
Usando webgpu-dev-extension puedes forzar a tu aplicación a usar el modo de compatibilidad como una prueba rápida sin cambios en tu aplicación. También puedes probar si una aplicación que se actualiza automáticamente a WebGPU core funciona cuando recibe el modo de compatibilidad.
Pasos:
-
Abre las herramientas de desarrollo (devtools) y ejecuta tu aplicación.
-
En Devtools, abre los ajustes (settings).
-
Activa ‘Custom Formatters’.
-
En WebGPU-Dev-Extension, selecciona estas opciones:
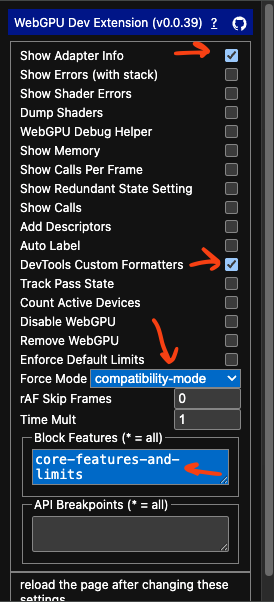
-
Force Mode: ‘compatibility-mode’
Esto hace que la aplicación ejecute
navigator.gpu.requestAdapter({ featureLevel: 'compatibility' });.Déjalo en el valor por defecto si tu aplicación ya admite el modo de compatibilidad.
-
Block Features ‘core-features-and-limits’
Esto hace que la aplicación no pueda solicitar el modo core.
-
DevTools Custom Formatters
Esto hace que, si inspeccionas el dispositivo en devtools, muestre
device.featurescomo un array de cadenas de texto. Sin esto, devtools muestra un objeto opaco y no puedes ver las características. -
Show Adapter Info
Esta opción hace que se ejecute
console.log(adapter)yconsole.log(device)cada vez que se crea un nuevo adaptador o dispositivo. Esto te permite verificar que el dispositivo está en el modo de compatibilidad. Puedes comprobardevice.featuresy ver que no tiene'core-features-and-limits'.
-
-
Refresca la página.
-
Verifica que tu aplicación se está ejecutando en el modo de compatibilidad.
En la consola de JavaScript deberías ver algo como esto:
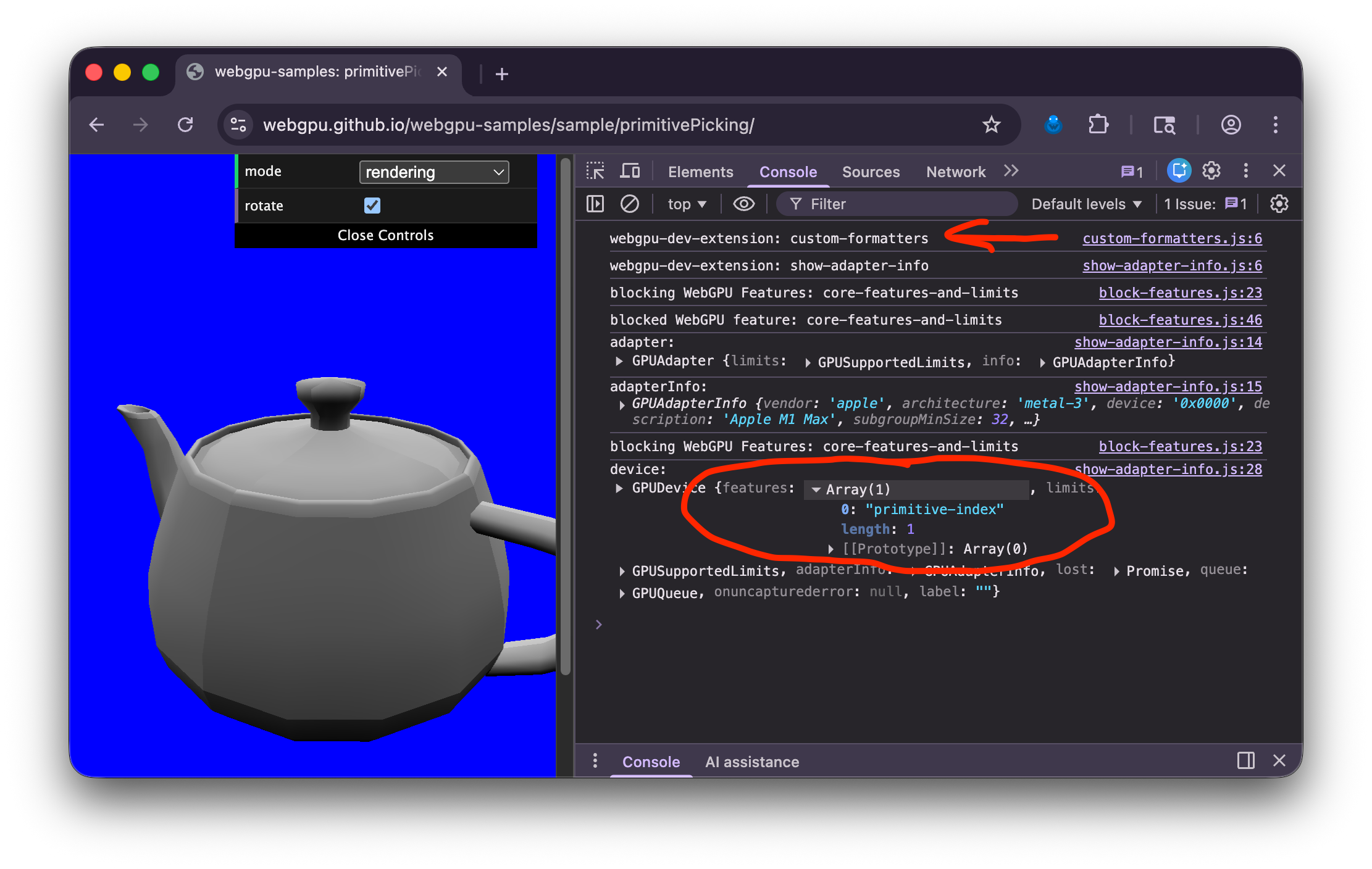
Busca webgpu-dev-extension: custom-formatters cerca de la parte superior para verificar que los formateadores
fueron inyectados en la página.
Luego, busca GPUDevice y expande las features. Asegúrate de que NO VES
"core-features-and-limits".
Ejemplos:
A partir del 2026-02-01, todos los ejemplos locales en webgpu-samples funcionan, y 185 de los 193 ejemplos de WebGPU en threejs.org/examples funcionan en el modo de compatibilidad. Los 8 restantes podrían actualizarse para que también funcionen en el modo de compatibilidad en el futuro con ajustes menores.
Copyright © 2023 World Wide Web Consortium. W3C® liability, trademark and permissive document license rules apply.